数据转换-union
数据转换使用操作符(operator)将一个或多个数据流转换为新的数据流。转换输入可以是一个或多个数据流,转换输出也可以是零个、一个或多个数据流。程序可以将多个转换组合成复杂的数据流拓扑。
union转换
union函数执行两个或多个数据流的联合。对两个或者两个以上的 DataStream 进行 union 操作,产生一个包含所有DataStream元素的新 DataStream。
在DataStream上使用union操作可以合并多个同类型的数据流,并生成同类型的数据流,即可以将多个DataStream[T]合并为一个新的DataStream[T]。数据将按照先进先出(First In First Out)的模式合并,且不去重。下图union对白色和深色两个数据流进行合并,生成一个数据流。
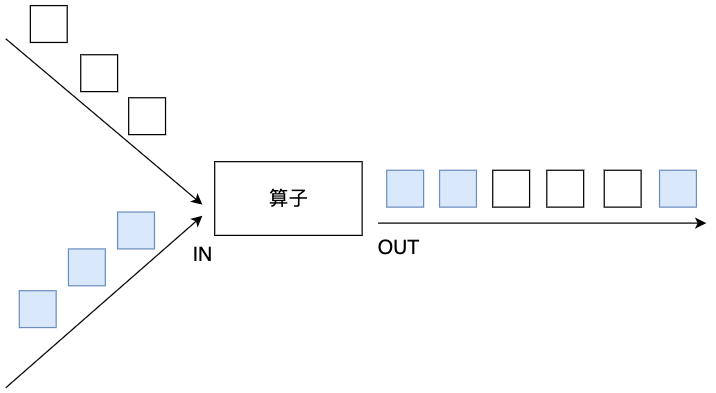
下面是进行union转换的示例代码。
Scala代码:
import org.apache.flink.streaming.api.scala._
/**
* union转换
*/
object TransformerUnion {
def main(args: Array[String]): Unit = {
// 设置流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// union
// 第一个数据集
val ds1 = env.fromElements("good good study").flatMap(_.toLowerCase.split("\\W+")).map( (_, 1))
// 第二个数据集
val ds2 = env.fromElements("day day up").flatMap(_.toLowerCase.split("\\W+")).map { (_, 1) }
// 合并两个数据集并输出
ds1.union(ds2).print()
// 执行
env.execute("flink union transformatiion")
}
}
Java代码:
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* union转换
*/
public class TransformerUnion {
public static void main(String[] args) throws Exception {
// 设置流执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// union转换
// 第一个数据集
DataStream<String> ds1 = env.fromElements("good good study")
.map(String::toLowerCase)
.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
for(String word: value.split("\\W+")){
out.collect(word);
}
}
});
DataStream<Tuple2<String, Integer>> ds1_map =
ds1.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
return new Tuple2<>(s, 1);
}
});
// 第二个数据集
DataStream<String> ds2 = env.fromElements("day day up")
.map(String::toLowerCase)
.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
for(String word: value.split("\\W+")){
out.collect(word);
}
}
});
DataStream<Tuple2<String, Integer>> ds2_map =
ds2.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
return new Tuple2<>(s, 1);
}
});
// 合并两个数据集并输出
DataStream<<Tuple2<String, Integer>> ds1_and_ds2 = ds1_map.union(ds2_map);
ds1_and_ds2.print();
// 执行
env.execute("flink union transformatiion");
}
}
执行以上代码,输出结果如下所示:
6> (good,1) 7> (day,1) 7> (day,1) 7> (up,1) 6> (good,1) 6> (study,1)
