使用IntelliJ IDEA+Maven开发Flink项目
通过结合使用IntelliJ IDEA集成开发工具和Maven项目构建工具,我们可以方便快速地开发Flink项目。
在IntelliJ IDEA中创建Flink项目
第一步:启动IntelliJ IDEA,创建一个新的项目,如下图所示:

第二步:选择Maven项目,并选择“Create from archetype”:
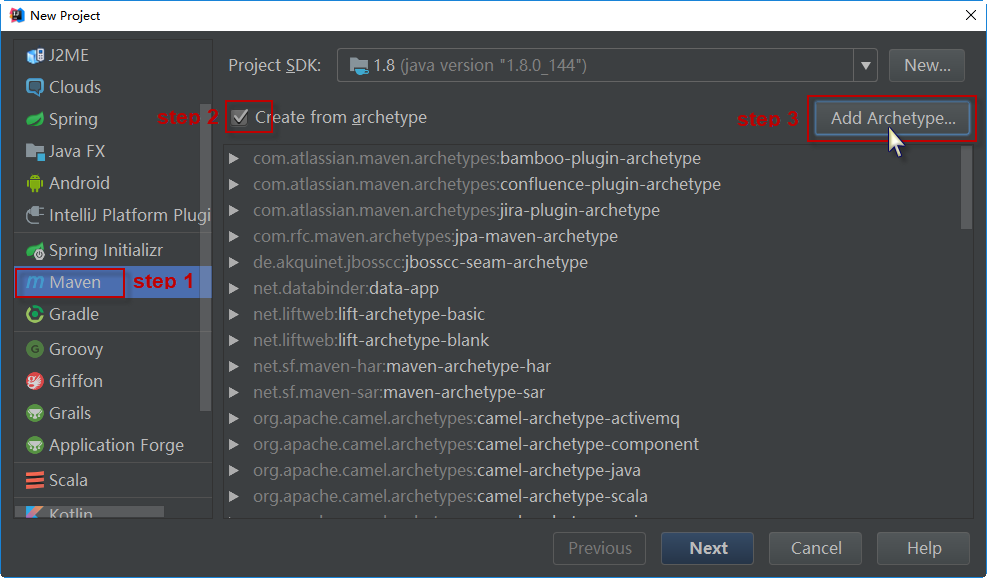
第三步:因为默认没有Flink的archetype,所以需要自己添加。
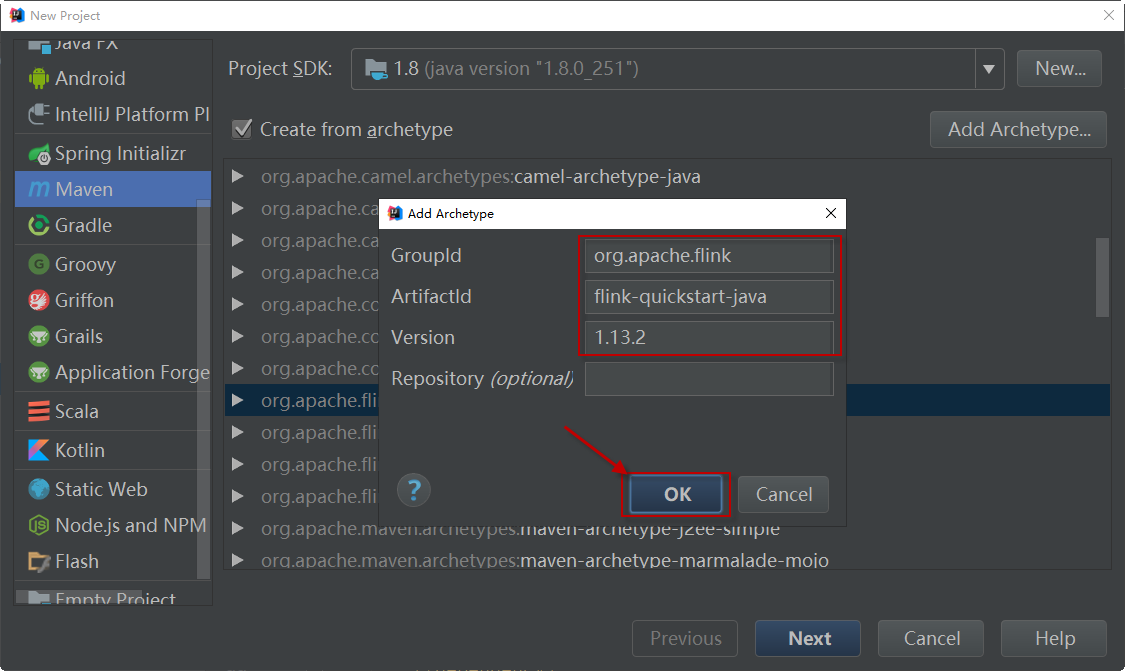
添加flink-quickstart-java的archetype如下图:
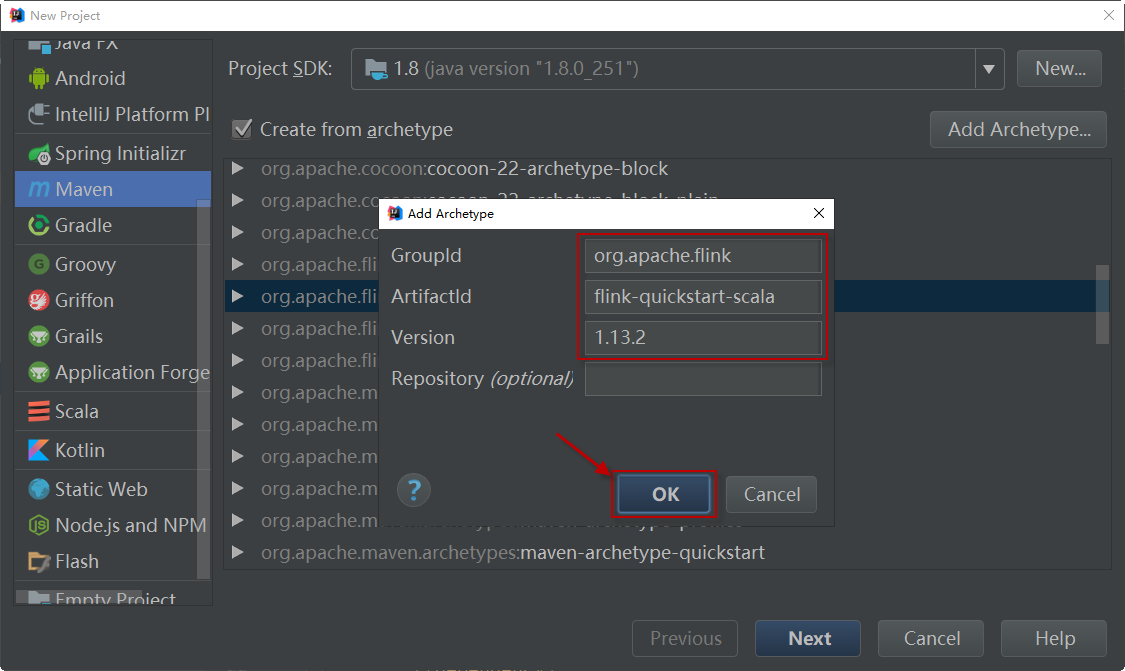
添加flink-quickstart-scala的archetype如下图:
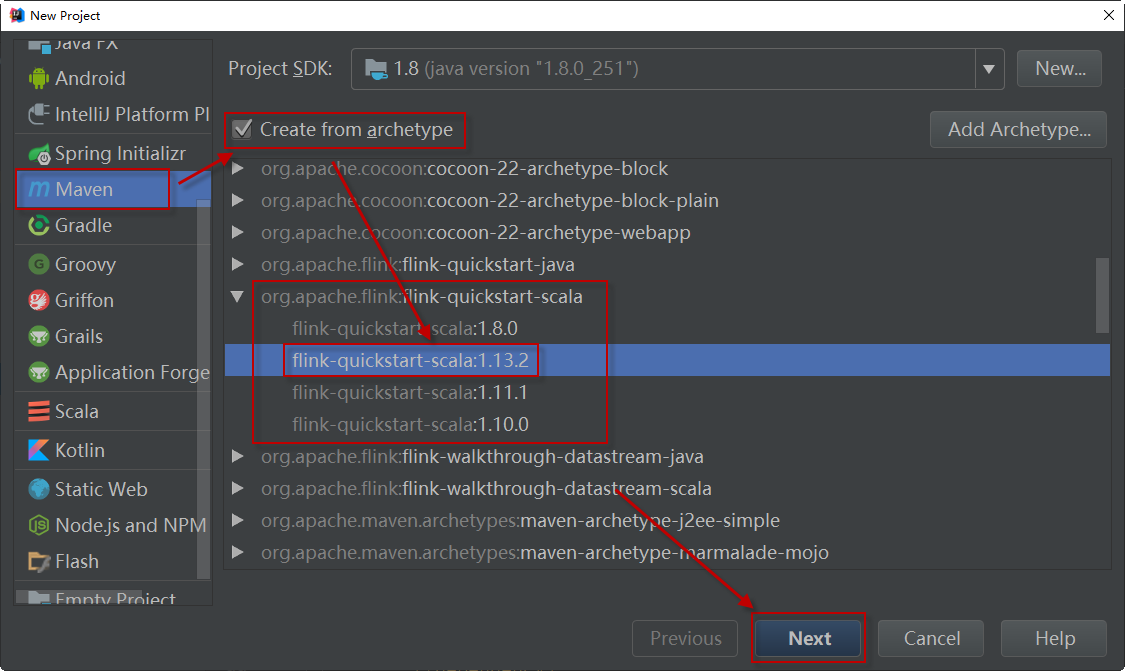
第四步:选择对应的archetype,比如,这里我选择flink-quickstart-scala,如下所示:
第五步:指定项目的groupId、artifactId名称。这里我分别取以下名称:
- groupId:com.xueai8
- artifactId:FlinkScalaDemo

第六步:接下来,指定项目的Maven配置,默认就好。
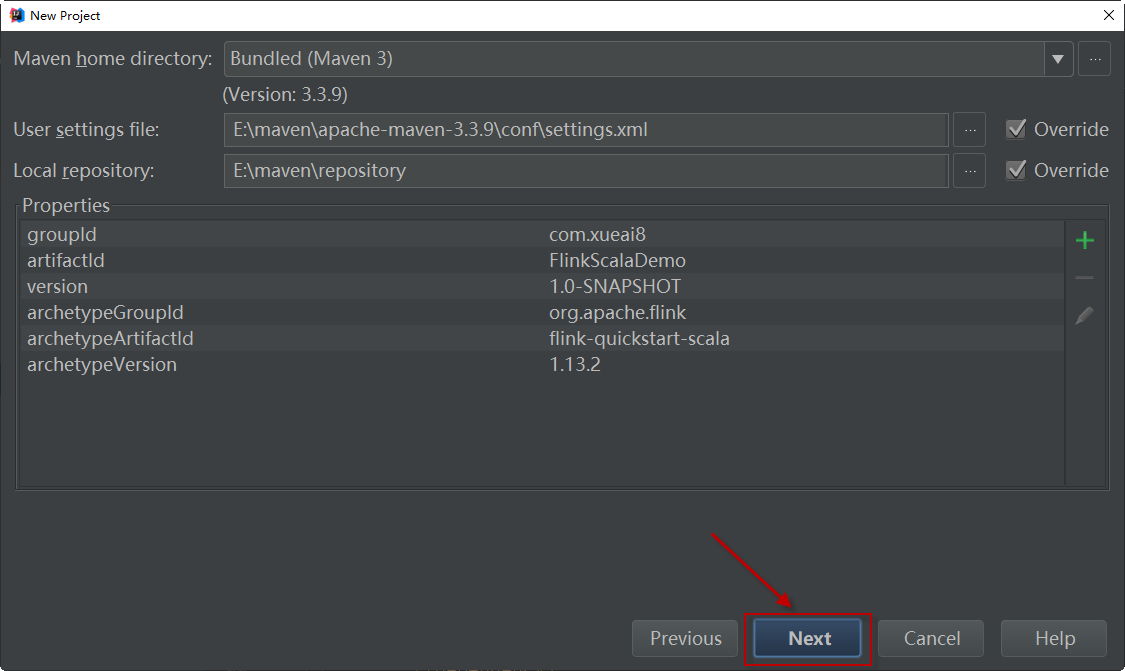
第七步:指定项目的名称和项目文件所在位置。这里保持默认即可。单击【Finish】按钮,开始创建项目:
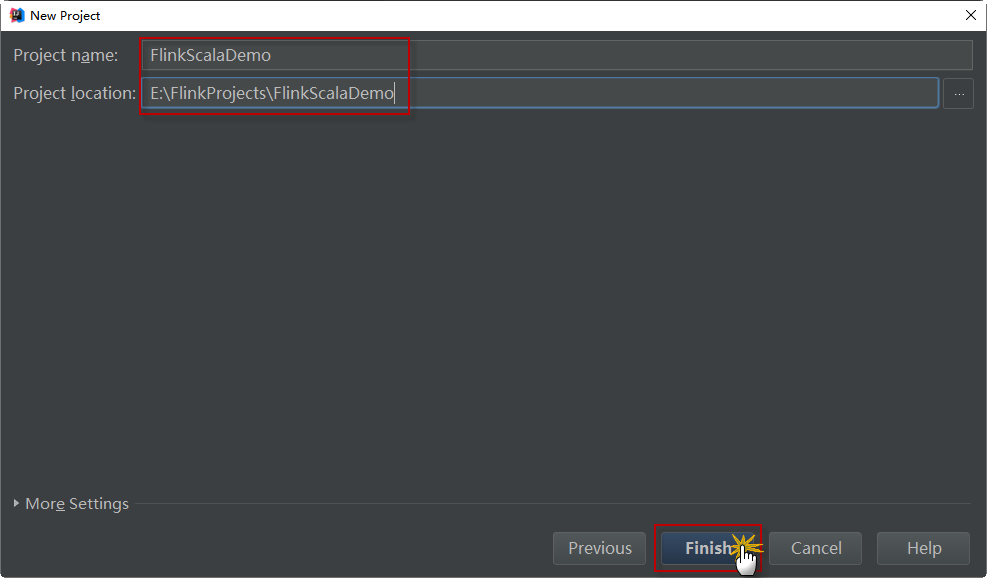
第八步:Maven会自动构建项目,最后的项目结构如下所示:

可以看出,flink-quickstart-scala快速地构建了一个基本的Flink项目框架,并生成创建了两个模板程序文件:用于流处理的StreamingJob和用于批处理的BatchJob。
注:同样的步骤,选择flink-quickstart-java,创建一个基于Java API的Flink项目框架。请自行尝试。
编写批处理代码并测试执行
以上一节所创建项目中的BatchJob源文件为模板,进一步编写一个简单的批处理代码并执行。这里的目的是为了掌握使用IntelliJ IDEA创建Flink Maven项目,所以不必理解代码,在后续的章节中会详细讲解。
在IntelliJ IDEA中打开BatchJob源文件,编辑代码如下。
Scala代码:
package com.xueai8
import org.apache.flink.api.scala._
object BatchJob {
def main(args: Array[String]) {
// 设置批执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 得到输入数据
val text = env.fromElements("good good study", "day day up")
// 对数据进行转换
val counts = text.flatMap { _.toLowerCase.split("\\W+") }
.map { (_, 1) }
.groupBy(0)
.sum(1)
// 执行并输出结果
counts.print()
}
}
Java代码:
package com.xueai8;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* 要打包应用程序为JAR文件,在命令行执行如下命令:
* $ mvn clean package
*
* 如果改变了主类的名称,那么需要在pom.xml文件中做相应的修改(简单搜索'mainClass')
*/
public class BatchJob {
public static void main(String[] args) throws Exception {
// 设置批处理执行环境
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 读取数据源
DataSet text = env.fromElements("Good good study", "Day day up");
// 对数据集进行转换
DataSet> result = text
.flatMap(new FlatMapFunction>() {
@Override
public void flatMap(String s, Collector> out) throws Exception {
String line = s.toLowerCase();
for(String word : line.split(" ")){
out.collect(new Tuple2<>(word, 1));
}
}
})
.groupBy(0)
.sum(1);
result.print();
}
}
在文件内任何空白处,单击右键,在弹出菜单中选择“run BatchJob”,执行该程序,在下方的运行窗口可以看到如下输出结果:
(up,1) (day,2) (good,2) (study,1)
项目打包并提交Flink集群执行
项目如果想要部署到生产环境运行,那么就要先打成jar包再进行部署。我们使用Maven的“mvn clean package”命令可以很方便地进行打包。具体操作步骤如下:
1、打开项目中的pom.xml文件,找到以下内容并修改mainClass(可Ctrl + F,查找查找mainClass)为当前类的全限定名称:
<transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>com.xueai8.BatchJob</mainClass> </transformer> </transformers>
2、在IntelliJ IDEA界面最下方左侧,点击Terminal选项卡,打开Terminal窗口。在Terminal窗口中执行命令“mvn clean package”命令打包项目:
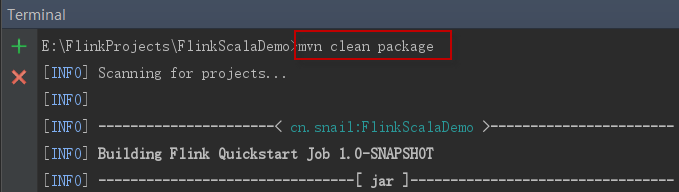
3、会编译打包过程中会输出一系列信息,如下所示:

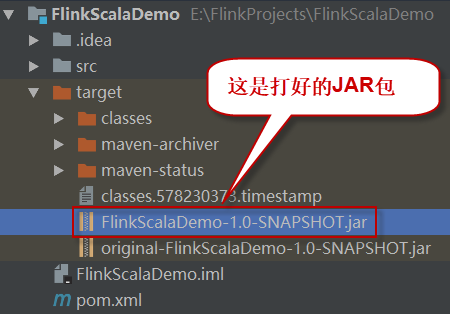
4、在项目下会生成一个target目录,打好的JAR包就在这里,如下图所示:
5、在Linux终端中,执行以下命令,启动Flink集群:
$ cd ~/bigdata/flink-1.13.2/ $ ./bin/start-cluster.sh
过程如下图所示:

6、将该JAR拷贝到Linux的指定目录下,例如,“~/flinkdemos/”目录下。然后提交到Flink集群上运行Job作业:
$ cd ~/bigdata/flink-1.13.2/ $ ./bin/flink run --class com.xueai8.BatchJob ~/flinkdemos/FlinkScalaDemo-1.0-SNAPSHOT.jar
执行结果如下所示:
(day,2) (good,2) (study,1) (up,1)
