HBase数据备份与还原
HBase是一个基于LSM树(log-structured merge-tree)的分布式数据存储系统,它使用复杂的内部机制确保数据准确性、一致性、多版本等。
如何获取数十个region server在HDFS和内存中的存储的众多HFile文件、WALs(Write-Ahead-Logs)的一致的数据备份? HBase提供了多种方式:(顺序:最小的破坏性 --> 最具破坏性)
- Snapshots
- Replication
- Export
- CopyTable
- HTable API
- Offline backup of HDFS data
这几种备份方法的比较如下表所示:
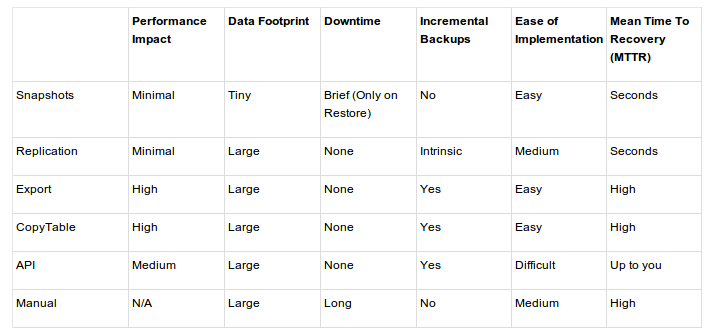
下面我们对常用的几种方式加以说明。
Snapshots(快照)
HBase快照功能丰富,有很多特征,并且创建时不需要关闭集群。
通过在HBase shell中运行如下命令来创建一个表的快照:
hbase(main):001:0> snapshot 'myTable', 'MySnapShot'
想要恢复数据只需要执行在shell中执行如下命令:
hbase(main):002:0> disable 'myTable' hbase(main):003:0> restore_snapshot 'MySnapShot' hbase(main):004:0> enable 'myTable'
快照实现原理如下图所示:
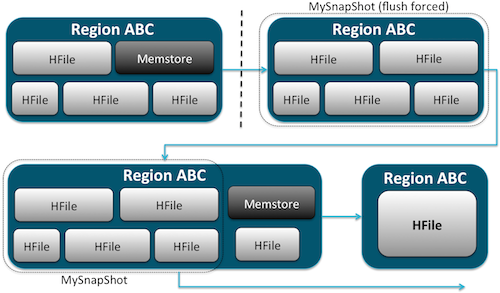
恢复快照需要对表进行离线操作。一旦恢复快照,那任何在快照时刻之后做的增加/更新数据都会丢失。快照是你的表在某一个时刻的完整图像,目前没有增量快照功能可用。
HBase复制(Replication)
HBase复制是另外一个负载较轻的备份工具。
复制有三种模式:主->从(master->slave)、主<->主(master<->master)和循环(cyclic)
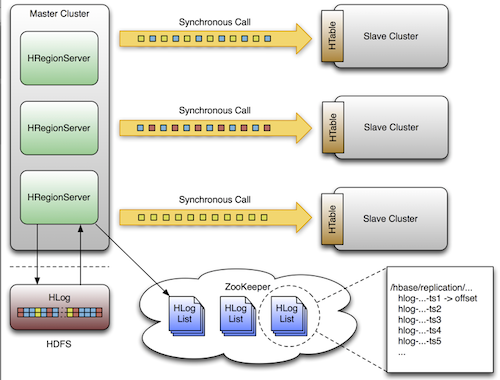
复制是一个强大的,容错的过程。它提供了“最终一致性”,意味着在任何时刻,最近对一个表的编辑可能无法应用到该表的所有副本,但是最终能够确保一致。
集群复制架构图如下所示:
导出(Export)与导入(Import)
HBase的导出工具是一个内置的实用功能,它使数据很容易从HBase表导入为HDFS目录下的SequenceFiles文件。
它创造了一个MapReduce任务,通过一系列HBase API来调用集群,获取指定表格的每一行数据,并且将数据写入指定的HDFS目录中。
这个工具对集群来讲是性能密集的,因为它使用了MapReduce和HBase 客户端API。但是它的功能丰富,支持制定版本或日期范围,支持数据的筛选,从而使增量备份可用。
导出表的命令:
hbase org.apache.hadoop.hbase.mapreduce.Export
恢复表的命令(导入时必须先创建表结构):
hbase org.apache.hadoop.hbase.mapreduce.Import
一旦表导出了,我们就可以复制生成的数据文件到想存储的任何地方(比如异地/离线集群存储)。
拷贝表(CopyTable)
和Export功能类似,拷贝表也使用HBase API创建了一个MapReduce任务,以便从源表读取数据。不同的地方是拷贝表的输出是HBase中的另一个表,这个表可以在本地集群,也可以在远程集群。
例:拷贝名为test的表到集群中的另外一个表testCopy。
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=testCopy test
注:textCopy表必须先创建。
注意,这里有一个明显的性能开销,它使用独立的“put”操作来逐行的写入数据到目的表。如果表非常大,拷贝表将会导致目标region server上的memstore被填满,会引起flush操作并最终导致合并操作的产生,会有垃圾收集操作等等。
此外,必须考虑到在HBase上运行MapReduce任务所带来的性能影响。对于大型的数据集,这种方法的效果可能不太理想。
