HBase数据导入
要使用HBase,需要将现有的各种类型的数据库或数据文件中的数据导入HBase。常用的数据导入方法有四种:
- HBase客户端API调用方式:
- 在命令行使用put方法;
- 编程通过Java API导入;
- 针对大部分情况,它并非都是最高效的方式。当需要将海量数据在规定时间内载入HBase中时,效率问题体现得尤为明显。
- MapReduce 任务方式:
- 在命令行调用importtsv工具;
- 自定义MapReduce job;
- 可以导入其他格式的数据,使用编程来生成数据。这是而MapReduce是处理海量数据最有效的方式,可能也是HBase中加载海量数据唯一最可行的方法了。
- Bulk Load 工具方式:
- 在命令行调用bulk load工具;
- 在MapReduce程序中调用bulk load工具;
- 这种方式支持将海量数据高效地装载入HBase中(文本数据)。Bulk load是通过一个MapReduce Job来实现的;使用bulk load功能最简单的方式就是使用importtsv 工具。
- Sqoop 工具方式:
- 使用sqoop将mysql中的数据导入到HBase表中;
- Sqoop 是 Apache 顶级项目,主要用于在 Hadoop(Hive) 与传统的数据库 (mysql、postgresql 等等) 之间进行数据的传递。Sqoop支持并行导入/导出数据,使用多个Map tasks,还支持在外部RDBMS上减少reduce加载。
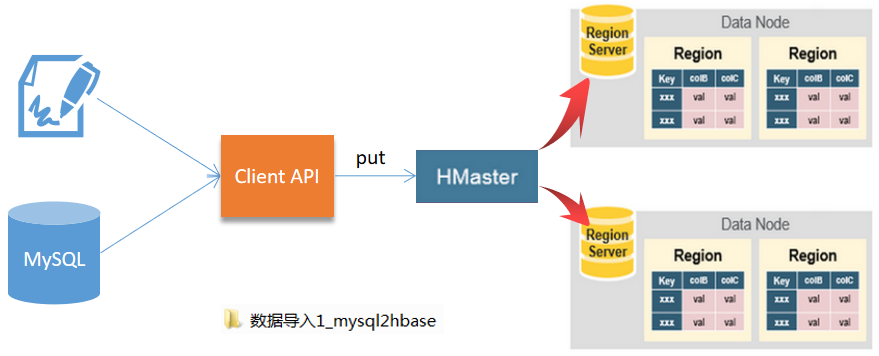
使用客户端API方式
需求:从已经存在的关系型数据库将数据导入到HBase中。
方式:从一个单独的客户端获取数据,然后通过HBase的Java API中put方法将数据存入HBase中。
应用场景:适合处理数据不是太多的情况。
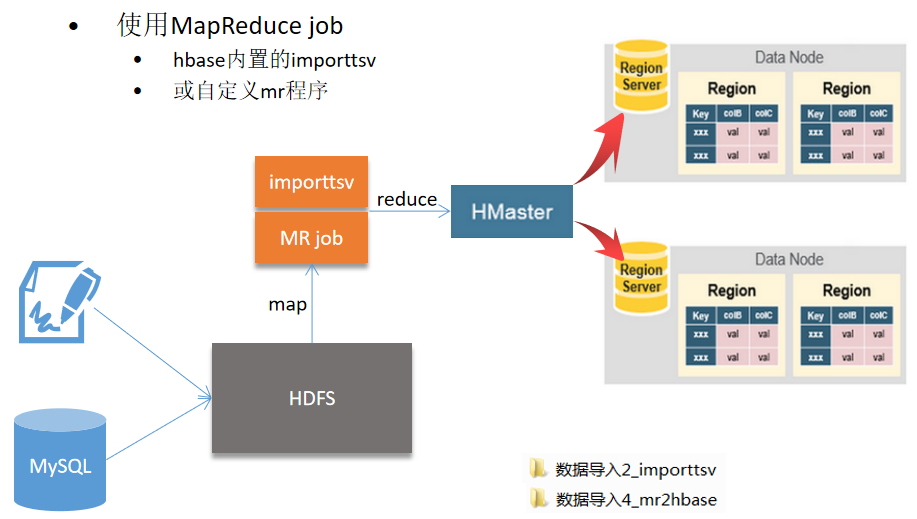
使用MapReduce job的方式
需求:使用这种方式,可以导入不同格式的数据,使用编程来生成数据。
方式:使用Hbase内置的importtsv工具,或者自定义一个MapReduce程序。
应用场景:适合海量数据的导入,或不同格式的导入数据。importtsv工具实际上就是HBase自带的MapReduce程序,可以并行执行。
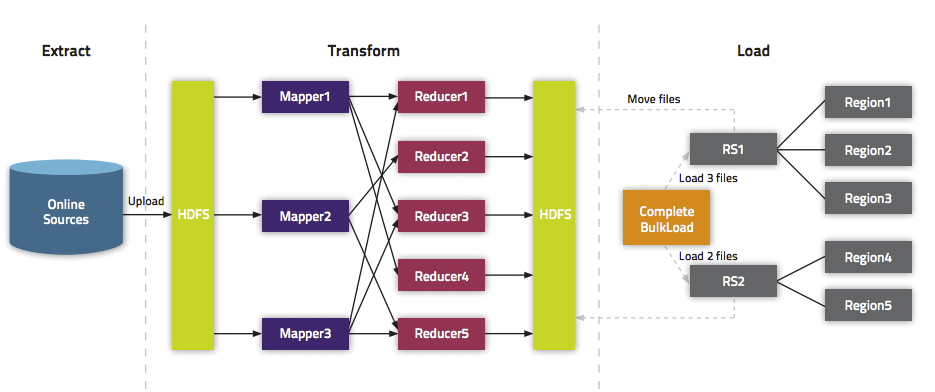
使用MapReduce job + bulk load的方式
需求:需要快速导入海量数据时。
方式:先使用MapReduce job直接生成HBase的hfile格式文件,然后再用再使用bulk load快速导入。
Bulk load是通过一个MapReduce Job来实现的,通过Job直接生成一个HBase的内部HFile格式文件来形成一个特殊的HBase数据表,然后直接将数据文件加载到运行的集群中。
使用bulk load功能最简单的方式就是使用importtsv 工具。importtsv 是从TSV文件直接加载内容至HBase的一个内置工具。它通过运行一个MapReduce Job,将数据从TSV文件中直接写入HBase的表或者写入一个HBase的自有格式数据文件。
应用场景:需要快速导入少量数据,并且不需要故障恢复时。

使用内置的importtsv工具导入数据
HBase提供importtsv工具支持从TSV文件中将数据导入HBase。
importtsv的作用是用MapReduce的方式将HDFS上的TSV格式(默认制表符分隔\t,或者自定义分隔符的其他格式数据文件也可)的数据文件通过命令简单方便地导入到HBase中,对于海量数据装载入HBase非常有用,十分高效。注:Importtsv工具只从HDFS中读取数据,所以一开始我们需要将TSV文件从本地文件系统拷贝到HDFS中,使用的是hadoop fs -copyFromLocal命令。
如果是要从现有的关系型数据库中加载数据,也可以先将数据导入文本文件中,然后使用importtsv 工具导入HBase。
importtsv 工具不仅支持将数据直接加载进HBase的表中,还支持直接生成HBase自有格式文件(HFile),然后再用HBase的bulk load工具将生成好的文件直接加载进运行中的HBase集群。
Importtsv运行原理
Importtsv本身是一个在HBase的JAR文件中的JAVA类。我们通过hadoop的jar命令来运行该工具。这个命令会启动一个Java进程,并且自动添加所有的依赖。需要运行哪个JAR是通过指定hadoop jar命令的第一个参数。
Importtsv工具默认使用了HBase的Put API来将数据插入HBase表中,在map阶段使用的是TableOutputFormat 。但是当 -Dimporttsv.bulk.output输入选项被指定时,会使用HFileOutputFormat来代替在HDFS中生成HBase的自有格式文件(HFile)。而后我们能够使用completebulkload 来加载生成的文件到一个运行的集群中。
1、利用 ImportTsv 将csv文件导入到HBase
命令:
$ ./hbase org.apache.hadoop.hbase.mapreduce.ImportTsv \ -Dimporttsv.separator="|" \ -Dimporttsv.columns=HBASE_ROW_KEY,cf:f1,cf:f2,cf:f3,cf:f4,cf:f5,cf:f6,cf:f7 \ emp_tb \ /empdata
2、利用completebulkload 将数据导入到HBase
HBase支持bulkload 的入库方式,它是利用HBase的数据信息按照特定格式存储在HDFS内这一原理,直接在HDFS中生成持久化的hfile数据格式文件,然后上传至合适位置,即完成巨量数据快速入库的办法,配合MapReduce完成,高效便捷,而且不占用region资源,增添负载,在大数据量写入时能极大的提高写入效率,并降低对HBase节点的写入压力。
# 先通过ImportTsv生成hfile $ ./hbase org.apache.hadoop.hbase.mapreduce.ImportTsv \ -Dimporttsv.separator="|" \ -Dimporttsv.bulk.output=/hfile_tmp \ -Dimporttsv.columns=HBASE_ROW_KEY,cf:f1,cf:f2,cf:f3,cf:f4,cf:f5,cf:f6,cf:f7 emp_tb1 \ /empdata # 再通过completebulkload将数据导入表emp_tb2 $ hadoop jar lib/hbase-server-2.3.4.jar completebulkload /hfile_tmp emp_tb2
自定义MapReduce job实现数据导入
编写MR程序将HDFS数据导入到HBase中,这种方式完全控制整个加载过程。
HBase提供TableOutputFormat类,用于在MapReduce中向HBase的表中写入数据。
也可以使用HFileOutputFormat类在MapReduce Job中直接生成HBase自有格式文件HFile,然后使用completebulkload 工具加载至运行的HBase集群中。
使用Sqoop工具
通过Sqoop,可以向 HBase 写入数据。
Sqoop 本身是通过 MapReduce 机制来保证传输数据,从而提供并发特性和容错机制。
例如,使用 Sqoop 的 import 功能,将MySQL中的人员信息导入到 HBase。
$ sqoop import --connect jdbc:mysql:@cloud01:3306:pgdb //JDBC URL --username root //用户名 --password admin //密码 --query 'SELECT * FROM tb1 WHERE $CONDITIONS' // Sqoop支持多表query --split-by id //指定并行处理切分任务的列名,通常为主键 --hbase-table usertb //HBase 中的 Table --column-family info //HBase 中的 column-family
注意:
1) 将需要连接的数据库驱动文件拷贝至lib目录下;
2)hadoop2貌似需要5.1.30以后的mysql驱动版本,否则很可能报错。
小结
数据导入环节属于大数据应用的数据清洗部分。
需要尝试多种方式将数据导入进去,没有哪一种方法是唯一的选择。首先要根据用户的实际环境选择正确的方式。
总的来说,Bulk Load 方式是最快速的,我们可以优先选择它。
