HBase物理存储模型
从概念视图层面,HBase中的每个表是由许多行组成的,但是在物理存储层面 ,它是采用了基于列的存储方式。也就是说,HBase是一个“列式数据库”。
列式数据库采用DSM(Decomposition Storage Model, 分解存储模型)存储模型,以关系数据库中的属性或列为单位进行存储,关系中多个元组的同一属性值(或同一列值)会被存储在一起,而一个元组中不同属性值则通常会被分别存放于不同的磁盘页中。
列式数据库主要适合于批量数据处理和即席查询。
列式数据库的优点是:可以降低I/O开销,支持大量并发用户查询,其数据处理速度比传统方法快100倍,具有较高的压缩比。
Region
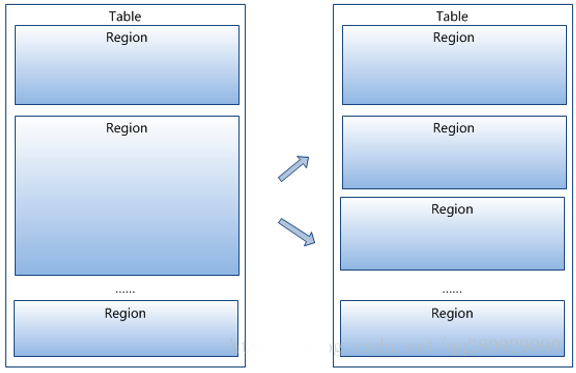
在HBase中,一张表可以由多个存放到不同服务器上的Region构成,HBase表、HRegion和存储文件之间的关系可由下图来示意。
在HBase表的物理存储中,采用了Region的概念,即HBase中的每张表默认只有一个Region(Region用于保存数据表中某段连续的数据,如存储数据表中的若干行)。
Region按大小分割的,每个表一开始只有一个Region,随着数据不断插入表,Region不断增大,当增大到一个阀值的时候,Region就会等分会两个新的Region。在物理存放时,Region会被存储至不同的HRegion Server上,形成分布式的存储模式。
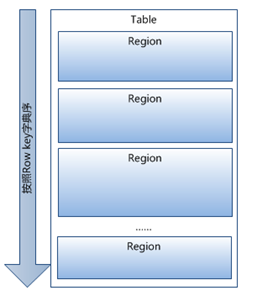
当表中的行不断增多,就会有越来越多的region。
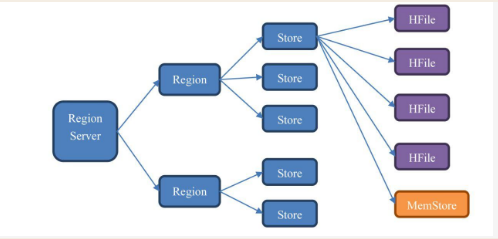
Store
Region虽然是分布式存储的最小单元,但并不是存储的最小单元。
Region由一个或者多个Store组成,每个Store保存一个columns family。每个Store又由一个memStore和0至多个StoreFile组成。

其中,MemStore是内存的存储对象,只有当MemStore满了之后Hbase会在HDFS上新生成一个新的Hfile,然后把 MemStore中的内容写到这个Hfile中,Hfile直接和HDFS打交道,是数据的存储实体。
HFile
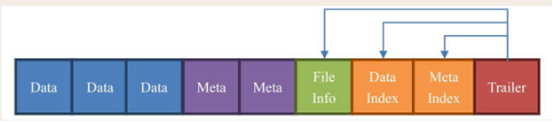
HFile是由一个一个的块组成的,在Hbase中一个快的大小默认为64kb,由列族上的BLOCKSIZE属性决定。这些块区分不同的角色:1)Data:数据块。每个HFile有多个Data块。我们存储在Hbase表中的数据就在数据块中。Data块其实是可选的,但是几乎很难看到不包含Date块的HFile。
2)Meta:元数据块。Meta也是可选的,Meta块只有在文件关闭的时候才会写入,Meta存储了该文件的元数据信息。
3)FileInfo:文件信息,其实也是一种数据存储快,FileInfo是HFile的必要组成部分。它只有在文件关闭的时候写入,存储的是这个文件的信息。
4)DataIndex:存储Date块索引信息的块文件。索引的信息其实也就是Data块的偏移量。DataIndex也是可选的,有Data块才有DataIndex。
5)Trailer:必选的,它存储了FileInfo,DateIndex,MetaIndex块的偏移量。