HBase逻辑模型
HBase是一个键值(key-value)型数据库,归属于NoSQL类型数据库。HBase数据行可以类比成一个多重映射(map),通过多重的键(key)一层层递进可以定位一个值(value)。因为HBase数据行列值可以是空白的(这些空白列是不占用存储空间的),所以HBase存储的数据是稀疏的。
HBase逻辑模型相关术语
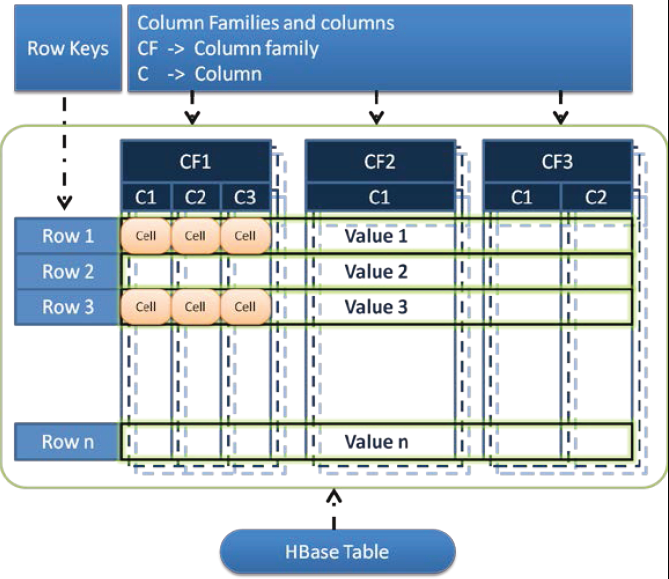
HBase数据存储结构中主要包括:表、行、列族、列限定符、单元格和时间戳等。在HBase中, 数据存储在表中,表具有行(row)和列(column)。
(1)命名空间(namespace):是逻辑上的一组表,等同于RDBMS中的数据库。命名空间管理:创建、删除和修改。有两个专门的预定义命名空间:hbase(系统命名空间, 用来包含HBase内部表)和default(没有显式指定命名空间的表会位于这个namespace)。
(2)表(table):类似于关系型数据库中的表,即数据行的集合。表名用字符串表示,一个表可以包含一个或者多个分区(region)。
(3)行(row):每一个row代表着一个数据对象,由一个 row key(行键)和一或多个具有值的 column 组成。
(4)行键(row key):是表中每个数据对象的唯一标识,以字节数组形式存储,类似于关系型数据库中表的主键。与 NoSQL 数据库一样,Row Key 是用来检索记录的主键。
(5)列族(column family):HBase是一个列式存储数据库,所谓列式就是根据列族存储,每个列族一个存储仓库(Store),每个Store有多个存储文件(StoreFile)用来存储实际数据。表中的每一row都有相同的column family。 访问控制、磁盘和内存的使用统计都是在列族层面进行的。column family 必须在 table 建立的时候声明。
(6)列限定符(column qualifier):每个列族可以有任意个列限定符用来标识不同的列,这个列也类似于关系型数据库表的一列,与关系型数据库不同的是列无须在表创建时指定,可以在需要使用时动态加入。column family 和 column qualifier 组成列(column),由冒号(:)分隔。
(7)单元格(cell):单元格由行键、列族、列限定符、时间戳、类型(Put、Delete等用来标识数据是有效还是删除状态)唯一决定,是HBase数据的存储单元,以字节码的形式存储。
(8)版本(version):cell中的每个value都会有一个 timestamp,作为该value特定版本的标识符。默认情况下,timestamp 代表数据被写入 RegionServer 的时间。row和column以字节(byte)存储,而version则是一个长整数 。 HBase version维度以降序存储,因此,当从store file中读取时,最近的值首先被读取。
(9)分区(region):分区是集群中高可用、动态扩展、负载均衡的最小单元,一个表可以分为任意个分区并且均衡分布在集群中的每台机器上,分区按行键分片,可以在创建表的时候预先分片,也可以在之后需要的时候调用HBase shell命令行或者API动态分片。
HBase 数据模型理解
下图为一个典型的HBase数据表,它由两个列族(Personal和Office)组成,每个列族都有两列。 包含数据的实体称为单元格,行根据行键进行排序。
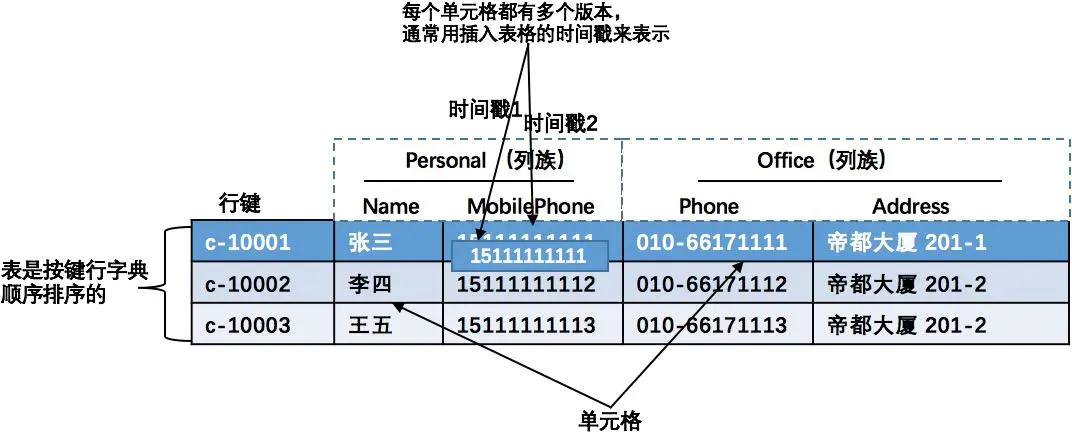
为了更好的理解HBase中的多维数据存储模型,在这里从上图的表中摘出一条数据,将它在HBase的表中的存储转化成如下图所表示的形式去理解。
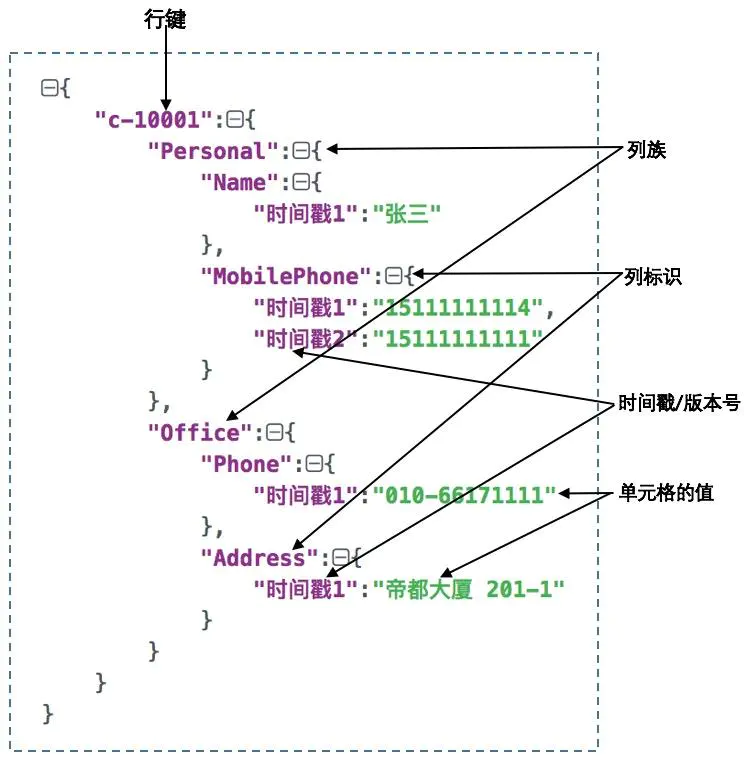
如果将HBase表中的数据理解成键值对存储的形式,那么也可以用如下图的形式来理解存储在HBase表中的数据。

