编程使用过滤器
HBase提供了大量的过滤器,可用于get或scan操作,只提取所需的数据。
在HBase中,get()和scan()方法支持直接访问数据并使用start key和end key。我们可以通过向HBase查询添加限制性的选择器来限制获取的数据的数量。这些选择器包括column families(列族)、column qualifiers(列限定符)、timestamps(时间戳)、ranges(范围)和version numbers(版本号)。
HBase的过滤器如下图所示:
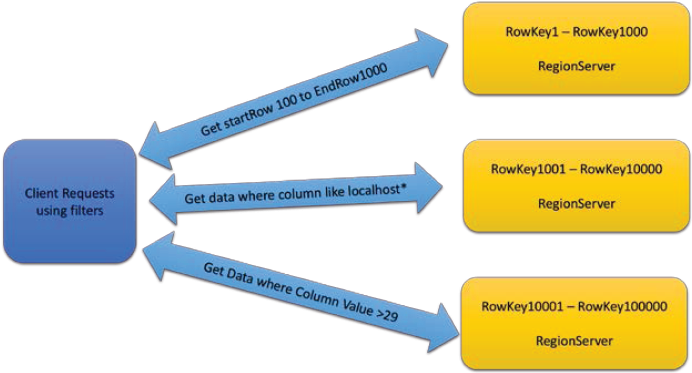
过滤器类型
下表是过滤器在比较时所依赖的运算符:
| 运算符类型 | 说明 |
|---|---|
| BitComparator.BitwiseOp | 执行按位比较。下面是它的枚举常量:
|
| CompareFilter.CompareOp | 这是一个用来进行比较的通用类型的过滤器。它可以使用操作符如相等、大于、不等于等。这还是一个byte[]比较器。下面是它的枚举常量:
|
| Filter.ReturnCode | 这些是用于过滤器值的返回码。下面是它的枚举常量:
|
| FilterList.Operator | 这些是用于一个filter list中多个过滤器的条件。下面是其枚举常量:
|
下表是HBase中提供的过滤器:
| 过滤器类型 | 说明 |
|---|---|
| BinaryComparator | 用于二进制字典顺序比较。它使用Bytes.compareTo(byte[], byte[])比较给定的字节数组 |
| BinaryPrefixComparator | 这是一个binary comparator filter,比较字节数组。但是只与这个字节数组的长度相比较 |
| BitComparator | 一个位比较器,它使用指定的字节数组对每个字节执行指定的位操 |
| ByteArrayComparable | 这是用于字节数组比较器的基类 |
| ColumnCountGetFilter | 这个过滤器只提供行中第一个N个列 |
| ColumnPaginationFilter | 这基于ColumnCountGetFilter; 它有两个参数,limit和offset, 用于分页 |
| ColumnPrefixFilter | 该过滤器用于获取与指定前缀相匹配的列的键 |
| ColumnRangeFilter | 这个过滤器用于在min-column和maxcolumn值之间选择列 |
| CompareFilter | 这是一个用于比较的通用过滤器 |
| DependentColumnFilter | 该过滤器用于添加与具有相应时间戳单元格相匹配的跨列时间戳 |
| FamilyFilter | 基于列族的过滤器 |
| Filter | 用于row和column的过滤器,可直接在RegionServer内应用 |
| FilterList | 使用这个,可以实现一个逻辑分区。这是一个有序的列表或一组过滤器。 可使用如下的比较运算符:
|
| FirstKeyOnlyFilter | 这个过滤器只返回每行的第一个KeyValue |
| FirstKeyValueMatchingQualifiersFilter | 这个过滤上器检查KeyValue中指定的列 |
| FuzzyRowFilter | 这个过滤器基于模糊 row keys |
| InclusiveStopFilter | 这个过滤器在给定的行之后停止 |
| KeyOnlyFilter | 这个过滤器将只返回每个KeyValue中的key组成部分 |
| MultipleColumnPrefixFilter | 这个过滤器用于选择与给定前缀匹配的列的key |
| NullComparator | 这是一个binary comparator; 按字典顺序与给定的字节数组进行比较,使用Bytes.compareTo (byte[], byte[]) |
| PageFilter | 这个过滤器限定结果到一个指定的分页大小 |
| ParseConstants | 持有一系列与(被ParseFilter使用的)解析过滤器字符串相关的常量 |
| ParseFilter | 这个过滤器允许用户通过一个字符串指定一个过滤器 |
| PrefixFilter | 这将返回具有相同行前缀的结果 |
| QualifierFilter | 这是基于列限定符的过滤器 |
| RandomRowFilter | 基于随机选择的行的过滤器 |
| RegexStringComparator | 这是一个基于正则表达式的过滤器 |
| RowFilter | 这被用来基于row key进行过滤的过滤器 |
| SingleColumnValueExcludeFilter | 检查一个单列的值,但并不返回被测试的列 |
| SingleColumnValueFilter | 这被用于基于值进行过滤的过滤器 |
| SkipFilter | 过滤一整行的过滤器,如果任何一个行单元格检查不满足比较条件的话 |
| SubstringComparator | 这是基于一个值中的子字符串进行比较的比较器 |
| TimestampsFilter | 这是一个基于数据的时间戳的过滤器 |
| ValueFilter | 这个过滤器基于列值 |
| WhileMatchFilter | 这个过滤器会一直继续,直到发现匹配的项 |
使用过滤器示例
下面是使用过滤器的示例代码。
// 使用过滤器
public static void get(String tableName, String family, String qualifier, String substring) throws IOException {
Table table = connection.getTable(TableName.valueOf(tableName)); // 表
Scan scan = new Scan();
// SubstringComparator用来判断一个给定的子字符串是否出现在给定列的单元格值中。不区分大小写
// 对于这个比较器,只有 EQUAL或NOT_EQUAL测试是有效的
ValueFilter valueFilter = new ValueFilter(CompareOp.EQUAL, new SubstringComparator(substring));
scan.setFilter(valueFilter); // 设置过滤器
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
byte[] value = result.getValue(Bytes.toBytes(family), Bytes.toBytes(qualifier));
System.out.println(Bytes.toString(value));
}
scanner.close();
table.close();
}
// 联合使用多个过滤器
public static void get(String tableName, String family, String qualifier) throws IOException {
Table table = connection.getTable(TableName.valueOf(tableName)); // 表
Scan scan = new Scan();
// 使用FilterList,组合使用多个过滤器
FilterList filterList = new FilterList(Operator.MUST_PASS_ALL);
filterList.addFilter(new KeyOnlyFilter()); // 指定第一个过滤器
filterList.addFilter(new FirstKeyOnlyFilter()); // 指定第二个过滤器
scan.setFilter(filterList); // 设置
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
byte[] value = result.getValue(Bytes.toBytes(family), Bytes.toBytes(qualifier));
System.out.println("查询到满足条件的值为:" + Bytes.toString(value));
}
scanner.close();
table.close();
}
