PySpark中如何处理科学记数表示?
2022-03-04 20:25:57.0
最近,我正在研究PySpark过程,在这个过程中,需要对大的数字应用一些聚合。 输出的结果是准确的,但它是以指数格式或科学表示法的形式输出的。这在展示中绝对不好看。例如,1.0125000010125E-8,念作“E的负8次幂”。
另外,根据我的观察,如果通过JDBC连接从任何数据库读取数据,并且数据类型是DECIMAL且小数部分(scale)超过6,那么该值在Spark中被转换为指数格式。
如何在Spark中处理科学记数?
可以在Spark中使用format_number函数来处理科学符号。
没有直接的方法来配置和停止spark中的科学记数法,但是可以应用format_number函数以适当的十进制格式而不是指数格式显示数字。
让我们先创建一个用科学表示法表示的样本DataFrame。
from pyspark.sql.types import StructType,StructField, IntegerType
from pyspark.sql.functions import col,format_number
data = [
(1,1),
(2,12),
(3,123),
(4,1234),
(5,12345),
(6,123456),
(7,1234567),
(8,12345678),
(9,123456789)
]
schema = StructType([ \
StructField("id",IntegerType(),True),
StructField("val", IntegerType(), True)
])
df = spark.createDataFrame(data=data,schema=schema)
df.printSchema()
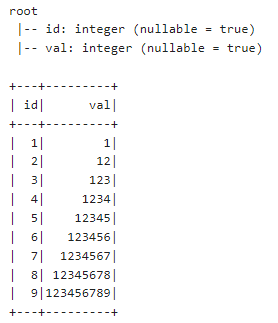
df.show()
执行以上代码,输出内容如下:
然后增加一个计算列new_val,其值由列val的值计算而来。
df1 = df.withColumn("new_val",col("val")/98765432)
df1.printSchema()
df1.select("id","val","new_val").show(truncate=False)
执行以上代码,输出内容如下:
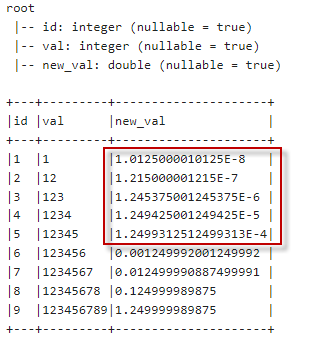
可以看到这些数值是以指数格式呈现的,即接近末尾的数字带有“E”。
现在我们不想看到科学符号的输出,所以将使用format_number函数进行处理。
df1.select("id","val",format_number(col("new_val"),10).alias("new_val")).show(truncate=False)
执行以上代码,输出内容如下:
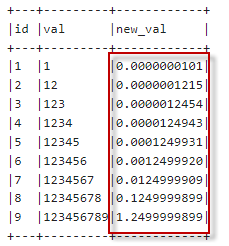
从结果可以看出,在Spark中可以使用“FORMAT_NUMBER”函数来处理双精度、浮点数或十进制的科学表示法。
补充
如想保留科学记数法,但是保留小数点后两位的数字。或者想把非科学记数法改成科学记数格式表示。 这时可以使用pyspark.sql.functions.format_string,它允许应用printf样式格式来显示结果。
from pyspark.sql.functions import col, format_string
df1.select("id","val",format_string("%.2e", col("new_val").cast('float')).alias("new_val")).show(truncate=False)
执行以上代码,输出内容如下:
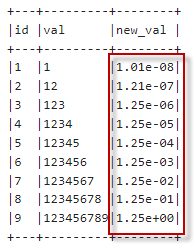
不过需要注意的是,这样得到的结果列是一个字符串(而不是数字)。
