现代数据湖存储层介绍
2022-02-18 11:05:57.0
近年来,我们看到了数据湖新存储层的增加。2017年,优步宣布了Hudi,一种用于数据管道的增量处理框架。2018年,Netflix推出了Iceberg,一种管理超大云数据集的新表格格式。2019年,Databricks开放了Delta Lake,最初打算将ACID事务引入数据湖。
这篇文章的目的是介绍这些引擎,并深入了解它们是如何运作的,以及它们之间的一些区别。关于所有这些框架,需要注意的一点是,每一个框架在开始时都有自己要解决的不同挑战,但随着时间的推移,它们开始集中于一组共同的功能。(请注意,因为我也在学习这些框架当中,所以这里的评价仅代表个人观点,既不权威也不全面。)
Apache Hudi
Apache Hudi (Hadoop Upsert Delete and Incremental)最初被设计为一个增量的流处理框架,其构建目的是将流和批处理的优点结合起来。Hudi可以用于Spark、Flink、Presto、Trino和Hive,但最初的大部分工作都是围绕着Spark进行的,所以本文的例子中我也是使用的Spark进行演示。Hudi的另一个巨大好处是自我管理数据层的概念。例如,Hudi可以自动执行异步压缩以优化数据湖,还支持多写入器保证。Hudi还根据读写需求和数据大小提供灵活的存储格式。
对于Hudi,我们创建了一个简单的Spark DataFrame,指定creation_date为分区字段,并将该DataFrame其写入S3。
# 创建一个DataFrame
inputDF = spark.createDataFrame(
[
("100", "2015-01-01", "2015-01-01T13:51:39.340396Z"),
("101", "2015-01-01", "2015-01-01T12:14:58.597216Z"),
("102", "2015-01-01", "2015-01-01T13:51:40.417052Z"),
("103", "2015-01-01", "2015-01-01T13:51:40.519832Z"),
("104", "2015-01-02", "2015-01-01T12:15:00.512679Z"),
("105", "2015-01-02", "2015-01-01T13:51:42.248818Z"),
],
["id", "creation_date", "last_update_time"],
)
# 在单个hudiOptions变量中指定通用DataSourceWriteOptions
hudiOptions = {
"hoodie.table.name": "my_hudi_table",
"hoodie.datasource.write.recordkey.field": "id",
"hoodie.datasource.write.partitionpath.field": "creation_date",
"hoodie.datasource.write.precombine.field": "last_update_time",
"hoodie.datasource.hive_sync.enable": "true",
"hoodie.datasource.hive_sync.table": "my_hudi_table",
"hoodie.datasource.hive_sync.partition_fields": "creation_date",
"hoodie.datasource.hive_sync.partition_extractor_class": "org.apache.hudi.hive.MultiPartKeysValueExtractor",
"hoodie.index.type": "GLOBAL_BLOOM", # 这是必要的,如果我们想确保upsert一条记录,即使分区改变
"hoodie.bloom.index.update.partition.path": "true", # 这是将数据写入新分区所必需的(在0.8.0中默认为false,在0.9.0中默认为true)
}
# 将一个DataFrame作为一个Hudi数据集写入
inputDF.write.format("org.apache.hudi").option(
"hoodie.datasource.write.operation", "insert"
).options(**hudiOptions).mode("overwrite").save(f"s3://{S3_BUCKET_NAME}/tmp/hudi/")
当我们查看S3上的文件结构时,我们看到了以下几点:
1. 一个hoodie.properties文件
2022-01-14 00:33:46 503 tmp/hudi/.hoodie/hoodie.properties
这个文件包含了关于Hudi数据集的某些元数据:
#Properties saved on Fri Jan 14 00:33:45 UTC 2022 #Fri Jan 14 00:33:45 UTC 2022 hoodie.table.precombine.field=last_update_time hoodie.table.partition.fields=creation_date hoodie.table.type=COPY_ON_WRITE hoodie.archivelog.folder=archived hoodie.populate.meta.fields=true hoodie.timeline.layout.version=1 hoodie.table.version=2 hoodie.table.recordkey.fields=id hoodie.table.base.file.format=PARQUET hoodie.table.keygenerator.class=org.apache.hudi.keygen.SimpleKeyGenerator hoodie.table.name=my_hudi_table
2. 一组与提交相关的文件
2022-01-14 00:33:57 2706 tmp/hudi/.hoodie/20220114003341.commit 2022-01-14 00:33:48 0 tmp/hudi/.hoodie/20220114003341.commit.requested 2022-01-14 00:33:52 1842 tmp/hudi/.hoodie/20220114003341.inflight
3. 实际的.parquet数据文件和相关联的元数据被组织到基于日期的分区中。
2022-01-14 00:33:54 93 tmp/hudi/2015-01-01/.hoodie_partition_metadata 2022-01-14 00:33:54 434974 tmp/hudi/2015-01-01/57f66198-5303-4922-9323-91737ec40d25-0_0-4-98_20220114003341.parquet 2022-01-14 00:33:55 93 tmp/hudi/2015-01-02/.hoodie_partition_metadata 2022-01-14 00:33:55 434943 tmp/hudi/2015-01-02/43051d12-87e7-4dfb-8201-6ce293cf0df7-0_1-6-99_20220114003341.parquet
然后我们更新这个数据集中一行的creation_date。
from pyspark.sql.functions import lit
# 通过修改inputDF中第一行的creation_date列值,从而创建一个新的DataFrame
updateDF = inputDF.where("id = 100").withColumn("creation_date", lit("2022-01-11"))
updateDF.show()
# 使用“upsert”操作进行更新
updateDF.write.format("org.apache.hudi").option(
"hoodie.datasource.write.operation", "upsert"
).options(**hudiOptions).mode("append").save(f"s3://{S3_BUCKET_NAME}/tmp/hudi/")
这里需要注意的是,由于我们正在更新分区值(危险!),我们必须将hoodie.index.type设置为GLOBAL_BLOOM,同时将hoodie.bloom.index.update.partition.path设置为true。这可能会对性能产生很大的影响,所以通常我们不会在生产环境中更改分区值,但是在这里可以看到它的影响。
在写入这个新的DataFrame后,我们在S3上有了一组新的提交相关文件:
2022-01-14 00:34:15 2706 tmp/hudi/.hoodie/20220114003401.commit 2022-01-14 00:34:03 0 tmp/hudi/.hoodie/20220114003401.commit.requested 2022-01-14 00:34:08 2560 tmp/hudi/.hoodie/20220114003401.inflight
实际上有两个新的.parquet文件
2022-01-14 00:34:12 434925 tmp/hudi/2015-01-01/57f66198-5303-4922-9323-91737ec40d25-0_0-37-13680_20220114003401.parquet ... 2022-01-14 00:34:13 93 tmp/hudi/2022-01-11/.hoodie_partition_metadata 2022-01-14 00:34:14 434979 tmp/hudi/2022-01-11/0c210872-484e-428b-a9ca-90a26e42125c-0_1-43-13681_20220114003401.parquet
因此,更新(update)发生的情况是,旧分区(2015-01-01)的数据被覆盖,新分区(2022-01-11)的数据也被写入。现在可以了解为什么全局bloom索引会对写性能产生如此大的影响,因为存在写放大的巨大潜力。
如果我们查询数据,并为每一行添加源文件名,我们也可以看到,旧分区的数据现在来自新的parquet文件(注意,提交ID 20220114003401出现在文件名中):
from pyspark.sql.functions import input_file_name
snapshotQueryDF = spark.read \
.format('org.apache.hudi') \
.load(f"s3://{S3_BUCKET_NAME}/tmp/hudi/") \
.select('id', 'creation_date') \
.withColumn("filename", input_file_name())
snapshotQueryDF.show(truncate=False)
输出内容如下:
+---+-------------+------------------------------------------------------------------------------------------------------------------------------+ |id |creation_date|filename | +---+-------------+------------------------------------------------------------------------------------------------------------------------------+ |100|2022-01-11 |/hudi/2022-01-11/0c210872-484e-428b-a9ca-90a26e42125c-0_1-43-13681_20220114003401.parquet | |105|2015-01-02 |/hudi/2015-01-02/43051d12-87e7-4dfb-8201-6ce293cf0df7-0_1-6-99_20220114003341.parquet | |104|2015-01-02 |/hudi/2015-01-02/43051d12-87e7-4dfb-8201-6ce293cf0df7-0_1-6-99_20220114003341.parquet | |102|2015-01-01 |/hudi/2015-01-01/57f66198-5303-4922-9323-91737ec40d25-0_0-37-13680_20220114003401.parquet | |103|2015-01-01 |/hudi/2015-01-01/57f66198-5303-4922-9323-91737ec40d25-0_0-37-13680_20220114003401.parquet | |101|2015-01-01 |/hudi/2015-01-01/57f66198-5303-4922-9323-91737ec40d25-0_0-37-13680_20220114003401.parquet | +---+-------------+------------------------------------------------------------------------------------------------------------------------------+
另一件需要注意的事情是,Hudi向Parquet文件添加了相当多的元数据。这些数据有助于启用记录级更改流(record-level change streams)。如果我们使用本地Spark读取一个Parquet文件并显示它,我们会看到有各种_hoodie前缀的键。
from pyspark.sql.functions import split
rawDF = (
spark.read.parquet(f"s3://{S3_BUCKET_NAME}/tmp/hudi/*/*.parquet")
.withColumn("filename", split(input_file_name(), "tmp/hudi").getItem(1))
.sort("_hoodie_commit_time", "_hoodie_commit_seqno")
)
rawDF.show(truncate=False)
可以看到如下的输出结果:
+-------------------+--------------------+------------------+----------------------+------------------------------------------------------------------------+---+-------------+---------------------------+------------------------------------------------------------------------------------+ |_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path|_hoodie_file_name |id |creation_date|last_update_time |filename | +-------------------+--------------------+------------------+----------------------+------------------------------------------------------------------------+---+-------------+---------------------------+------------------------------------------------------------------------------------+ |20220114003341 |20220114003341_0_1 |100 |2015-01-01 |57f66198-5303-4922-9323-91737ec40d25-0_0-4-98_20220114003341.parquet |100|2015-01-01 |2015-01-01T13:51:39.340396Z|/2015-01-01/57f66198-5303-4922-9323-91737ec40d25-0_0-4-98_20220114003341.parquet | |20220114003341 |20220114003341_0_2 |102 |2015-01-01 |57f66198-5303-4922-9323-91737ec40d25-0_0-4-98_20220114003341.parquet |102|2015-01-01 |2015-01-01T13:51:40.417052Z|/2015-01-01/57f66198-5303-4922-9323-91737ec40d25-0_0-37-13680_20220114003401.parquet| |20220114003341 |20220114003341_0_2 |102 |2015-01-01 |57f66198-5303-4922-9323-91737ec40d25-0_0-4-98_20220114003341.parquet |102|2015-01-01 |2015-01-01T13:51:40.417052Z|/2015-01-01/57f66198-5303-4922-9323-91737ec40d25-0_0-4-98_20220114003341.parquet | |20220114003341 |20220114003341_0_3 |103 |2015-01-01 |57f66198-5303-4922-9323-91737ec40d25-0_0-4-98_20220114003341.parquet |103|2015-01-01 |2015-01-01T13:51:40.519832Z|/2015-01-01/57f66198-5303-4922-9323-91737ec40d25-0_0-37-13680_20220114003401.parquet| |20220114003341 |20220114003341_0_3 |103 |2015-01-01 |57f66198-5303-4922-9323-91737ec40d25-0_0-4-98_20220114003341.parquet |103|2015-01-01 |2015-01-01T13:51:40.519832Z|/2015-01-01/57f66198-5303-4922-9323-91737ec40d25-0_0-4-98_20220114003341.parquet | |20220114003341 |20220114003341_0_4 |101 |2015-01-01 |57f66198-5303-4922-9323-91737ec40d25-0_0-4-98_20220114003341.parquet |101|2015-01-01 |2015-01-01T12:14:58.597216Z|/2015-01-01/57f66198-5303-4922-9323-91737ec40d25-0_0-37-13680_20220114003401.parquet| |20220114003341 |20220114003341_0_4 |101 |2015-01-01 |57f66198-5303-4922-9323-91737ec40d25-0_0-4-98_20220114003341.parquet |101|2015-01-01 |2015-01-01T12:14:58.597216Z|/2015-01-01/57f66198-5303-4922-9323-91737ec40d25-0_0-4-98_20220114003341.parquet | |20220114003341 |20220114003341_1_5 |105 |2015-01-02 |43051d12-87e7-4dfb-8201-6ce293cf0df7-0_1-6-99_20220114003341.parquet |105|2015-01-02 |2015-01-01T13:51:42.248818Z|/2015-01-02/43051d12-87e7-4dfb-8201-6ce293cf0df7-0_1-6-99_20220114003341.parquet | |20220114003341 |20220114003341_1_6 |104 |2015-01-02 |43051d12-87e7-4dfb-8201-6ce293cf0df7-0_1-6-99_20220114003341.parquet |104|2015-01-02 |2015-01-01T12:15:00.512679Z|/2015-01-02/43051d12-87e7-4dfb-8201-6ce293cf0df7-0_1-6-99_20220114003341.parquet | |20220114003401 |20220114003401_1_1 |100 |2022-01-11 |0c210872-484e-428b-a9ca-90a26e42125c-0_1-43-13681_20220114003401.parquet|100|2022-01-11 |2015-01-01T13:51:39.340396Z|/2022-01-11/0c210872-484e-428b-a9ca-90a26e42125c-0_1-43-13681_20220114003401.parquet| +-------------------+--------------------+------------------+----------------------+------------------------------------------------------------------------+---+-------------+---------------------------+------------------------------------------------------------------------------------+
在后台,Hudi根据提交文件和parquet文件中的元数据确定要显示哪些提交和值。
Apache Iceberg
当我第一次听说Iceberg时,“用于存储大型、移动缓慢的表格数据的表格格式”这个短语对我来说真的没有什么意义。但在对数据湖进行大规模研究后,情况变得相当清楚。Apache Hive是一个流行的数据仓库项目,它为大型数据集提供了一个类SQL的接口。它建立在Hadoop之上,最初使用HDFS作为数据存储。通过云迁移,Amazon S3这样的对象存储能够存储更多的数据,特别是不需要考虑大型Hadoop集群的操作问题,但与HDFS相比有一些限制。具体来说,目录列表变慢了(这里有简单的物理现象,网络调用变慢了),重命名不是原子的(设计上的),结果以前是最终一致的。
假设您是Netflix,有数百PB字节的数据存储在S3上,现在需要一种方法让您的组织有效地查询这些数据。您需要一个数据存储层来减少或删除目录列表,您希望进行原子更改,并且您希望确保在读取数据时得到一致的结果。
这是Iceberg最初的一些目标,所以让我们深入了解它是如何工作的。 与Hudi类似,我们将创建一个简单的Spark DataFrame,并将其以Iceberg格式写入S3。 应该注意的是,Iceberg的大部分内容都是围绕Spark SQL展开的,所以我将在下面讨论一些特定的操作。
# 创建一个DataFrame
inputDF = spark.createDataFrame(
[
("100", "2015-01-01", "2015-01-01T13:51:39.340396Z"),
("101", "2015-01-01", "2015-01-01T12:14:58.597216Z"),
("102", "2015-01-01", "2015-01-01T13:51:40.417052Z"),
("103", "2015-01-01", "2015-01-01T13:51:40.519832Z"),
("104", "2015-01-02", "2015-01-01T12:15:00.512679Z"),
("105", "2015-01-02", "2015-01-01T13:51:42.248818Z"),
],
["id", "creation_date", "last_update_time"],
)
# 将DataFrame作为一个Iceberg数据集写入
inputDF.write.format("iceberg").mode("overwrite").partitionBy("creation_date").option(
"path", f"s3://{S3_BUCKET_NAME}/tmp/iceberg/"
).saveAsTable(ICEBERG_TABLE_NAME)
这里有两个主要的区别——没有像使用Hudi时那么多的“配置”,而且我们也显式地使用saveAsTable。使用Iceberg,大部分元数据存储在数据目录(data catalog)中,因此有必要创建表。让我们看看S3上发生了什么。
1. 首先,有一个metadata.json文件
2022-01-28 06:03:50 2457 tmp/iceberg/metadata/00000-bb1d38a9-af77-42c4-a7b7-69416fe36d9c.metadata.json
2. 然后是快照清单列表(manifest list)文件
2022-01-28 06:03:50 3785 tmp/iceberg/metadata/snap-7934053180928033536-1-e79c79ba-c7f0-45ad-8f2e-fd1bc349db55.avro
3. 还有一个清单文件(manifest file)
2022-01-28 06:03:50 6244 tmp/iceberg/metadata/e79c79ba-c7f0-45ad-8f2e-fd1bc349db55-m0.avro
4. 最后,我们得到了Parquet数据文件
2022-01-28 06:03:49 1197 tmp/iceberg/data/creation_date=2015-01-01/00000-4-fa9a18fd-abc4-4e04-91b4-e2ac4c9531be-00001.parquet 2022-01-28 06:03:49 1171 tmp/iceberg/data/creation_date=2015-01-01/00001-5-eab30115-a1d6-4918-abb4-a198ac12b262-00001.parquet 2022-01-28 06:03:50 1182 tmp/iceberg/data/creation_date=2015-01-02/00001-5-eab30115-a1d6-4918-abb4-a198ac12b262-00002.parquet
下面的Iceberg规范图说明了这些文件之间的关系:
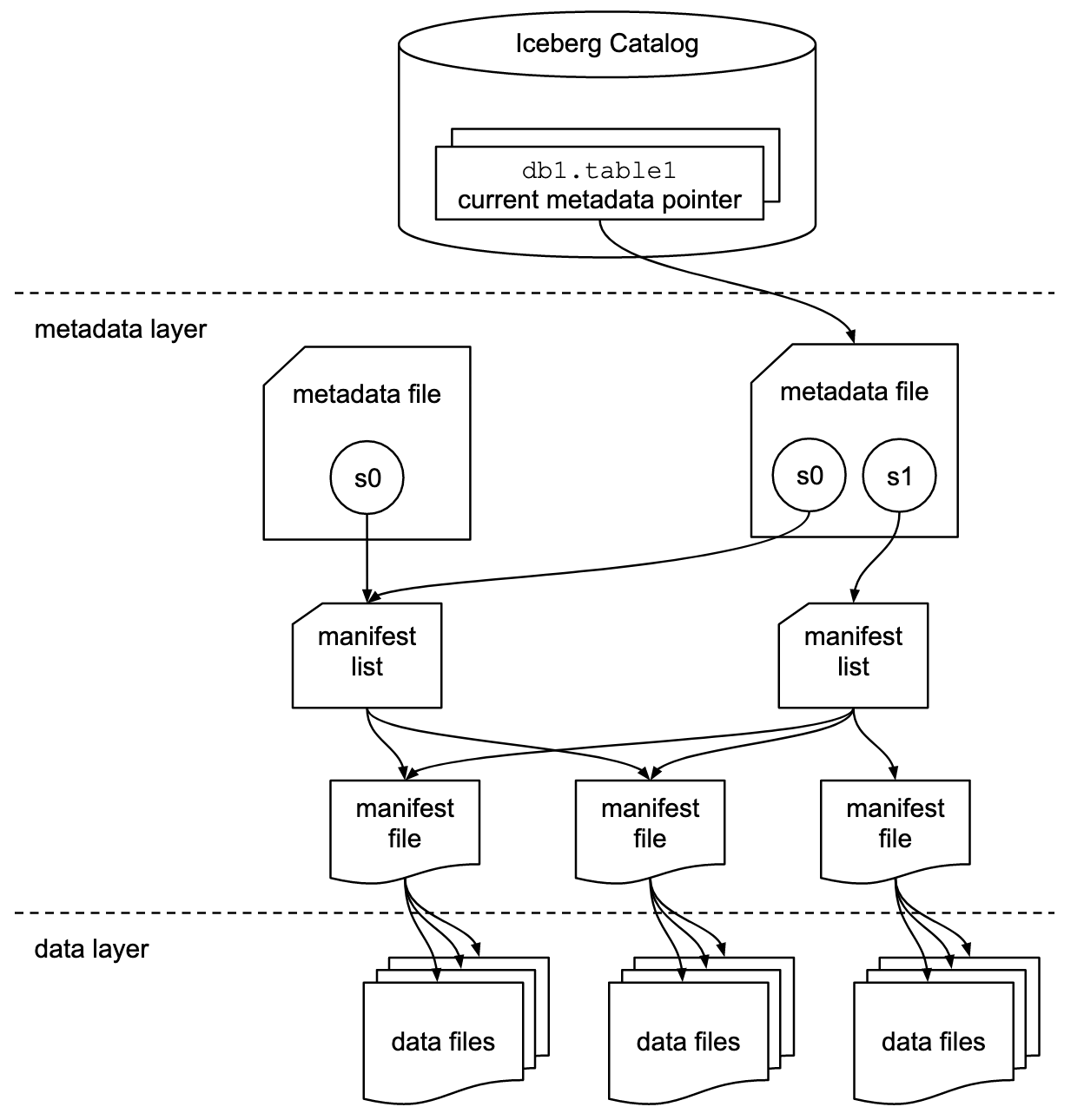
与Hudi类似,我们的数据被写入每个分区中的Parquet文件,尽管默认情况下使用Hive风格的分区。(Hudi也可以通过设置hoodie.datasource.write.hive_style_partitioning参数来实现Hive风格的分区)
但是,与Hudi不同的是,Iceberg默认使用数据目录(data catalog)来标识要使用的当前元数据文件。该元数据文件包含对清单文件列表的引用,用于确定哪个数据文件组成特定版本的数据集(也称为快照)。从0.7.0开始,它还支持元数据表,以减少文件清单对性能的影响。快照数据还包含相当多的附加信息。
接下来,我们更新数据集,然后再次看看S3和元数据文件的快照部分。
spark.sql(f"UPDATE {ICEBERG_TABLE_NAME} SET creation_date = '2022-01-11' WHERE id = 100")
可以看到:
2个新的.parquet数据文件
2022-01-28 06:07:07 1180 tmp/iceberg/data/creation_date=2015-01-01/00000-16-033354bd-7b02-44f4-95e2-7045e10706fc-00001.parquet 2022-01-28 06:07:08 1171 tmp/iceberg/data/creation_date=2022-01-11/00000-16-033354bd-7b02-44f4-95e2-7045e10706fc-00002.parquet
1个新的metadata.json文件
2个新的.avro元数据列表
1个新的snap-*.avro快照文件
让我们看看metadata.json文件的快照部分。
"snapshots": [
{
"manifest-list": "s3:///tmp/iceberg/metadata/snap-7934053180928033536-1-e79c79ba-c7f0-45ad-8f2e-fd1bc349db55.avro",
"schema-id": 0,
"snapshot-id": 7934053180928033536,
"summary": {
"added-data-files": "3",
"added-files-size": "3550",
"added-records": "6",
"changed-partition-count": "2",
"operation": "append",
"spark.app.id": "application_1643153254969_0029",
"total-data-files": "3",
"total-delete-files": "0",
"total-equality-deletes": "0",
"total-files-size": "3550",
"total-position-deletes": "0",
"total-records": "6"
},
"timestamp-ms": 1643349829278
},
{
"manifest-list": "s3:///tmp/iceberg/metadata/snap-5441092870212826638-1-605de48f-8ccf-450c-935e-bbd4194ee8cc.avro",
"parent-snapshot-id": 7934053180928033536,
"schema-id": 0,
"snapshot-id": 5441092870212826638,
"summary": {
"added-data-files": "2",
"added-files-size": "2351",
"added-records": "3",
"changed-partition-count": "2",
"deleted-data-files": "1",
"deleted-records": "3",
"operation": "overwrite",
"removed-files-size": "1197",
"spark.app.id": "application_1643153254969_0029",
"total-data-files": "4",
"total-delete-files": "0",
"total-equality-deletes": "0",
"total-files-size": "4704",
"total-position-deletes": "0",
"total-records": "6"
},
"timestamp-ms": 1643350027635
}
]
这是非常惊人的——我们可以看到有多少文件和记录被添加或删除,文件大小是多少,甚至是Spark app_id是什么! 其中一些数据也存在于manifest-list文件中,但是我们可以马上了解使用这些数据可以在多大程度上优化查询。
Delta Lake
Databricks也引入了Delta Lake,以解决数据湖面临的许多挑战。与Hudi和Iceberg类似,它的目标包括统一批处理和流处理、ACID事务和可伸缩元数据处理。
同样,我们将创建一个简单的Spark DataFrame,并将其以Delta格式写入S3。
# 创建一个DataFrame
inputDF = spark.createDataFrame(
[
("100", "2015-01-01", "2015-01-01T13:51:39.340396Z"),
("101", "2015-01-01", "2015-01-01T12:14:58.597216Z"),
("102", "2015-01-01", "2015-01-01T13:51:40.417052Z"),
("103", "2015-01-01", "2015-01-01T13:51:40.519832Z"),
("104", "2015-01-02", "2015-01-01T12:15:00.512679Z"),
("105", "2015-01-02", "2015-01-01T13:51:42.248818Z"),
],
["id", "creation_date", "last_update_time"],
)
# 将一个DataFrame作为一个Delta数据集写入
inputDF.write.format("delta").mode("overwrite").option(
"overwriteSchema", "true"
).partitionBy("creation_date").save(f"s3://{S3_BUCKET_NAME}/tmp/delta/")
在S3上,我们现在可以看到以下文件:
1. 一个00000000000000000000.json文件
2022-01-24 22:57:54 2120 tmp/delta/_delta_log/00000000000000000000.json
2. 多个.snappy.parquet文件
2022-01-24 22:57:52 875 tmp/delta/creation_date=2015-01-01/part-00005-2e09dbe4-469e-40dc-9b36-833480f6d375.c000.snappy.parquet 2022-01-24 22:57:52 875 tmp/delta/creation_date=2015-01-01/part-00010-848c69e1-71fb-4f8f-a19a-dd74e0ef1b8a.c000.snappy.parquet 2022-01-24 22:57:53 875 tmp/delta/creation_date=2015-01-01/part-00015-937d1837-0f03-4306-9b4e-4366207e688d.c000.snappy.parquet 2022-01-24 22:57:54 875 tmp/delta/creation_date=2015-01-01/part-00021-978a808e-4c36-4646-b7b1-ef5a21e706d8.c000.snappy.parquet 2022-01-24 22:57:54 875 tmp/delta/creation_date=2015-01-02/part-00026-538e1ac6-055e-4e72-9177-63daaaae1f98.c000.snappy.parquet 2022-01-24 22:57:52 875 tmp/delta/creation_date=2015-01-02/part-00031-8a03451a-0297-4c43-b64d-56db25807d02.c000.snappy.parquet
_delta_log文件里有什么? 与Iceberg类似,关于初始写入S3的大量信息,包括写入的文件数量、数据集的模式,甚至每个文件的add操作。
{
"commitInfo": {
"timestamp": 1643065073634,
"operation": "WRITE",
"operationParameters": {
"mode": "Overwrite",
"partitionBy": "[\"creation_date\"]"
},
"isBlindAppend": false,
"operationMetrics": {
"numFiles": "6",
"numOutputBytes": "5250",
"numOutputRows": "6"
}
}
}
{
"protocol": {
"minReaderVersion": 1,
"minWriterVersion": 2
}
}
{
"metaData": {
"id": "a7f4b1d1-09f6-4475-894a-0eec90d1aab5",
"format": {
"provider": "parquet",
"options": {}
},
"schemaString": "{\"type\":\"struct\",\"fields\":[{\"name\":\"id\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"creation_date\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"last_update_time\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}}]}",
"partitionColumns": [
"creation_date"
],
"configuration": {},
"createdTime": 1643065064066
}
}
{
"add": {
"path": "creation_date=2015-01-01/part-00005-2e09dbe4-469e-40dc-9b36-833480f6d375.c000.snappy.parquet",
"partitionValues": {
"creation_date": "2015-01-01"
},
"size": 875,
"modificationTime": 1643065072000,
"dataChange": true
}
}
{
"add": {
"path": "creation_date=2015-01-01/part-00010-848c69e1-71fb-4f8f-a19a-dd74e0ef1b8a.c000.snappy.parquet",
"partitionValues": {
"creation_date": "2015-01-01"
},
"size": 875,
"modificationTime": 1643065072000,
"dataChange": true
}
}
{
"add": {
"path": "creation_date=2015-01-01/part-00015-937d1837-0f03-4306-9b4e-4366207e688d.c000.snappy.parquet",
"partitionValues": {
"creation_date": "2015-01-01"
},
"size": 875,
"modificationTime": 1643065073000,
"dataChange": true
}
}
{
"add": {
"path": "creation_date=2015-01-01/part-00021-978a808e-4c36-4646-b7b1-ef5a21e706d8.c000.snappy.parquet",
"partitionValues": {
"creation_date": "2015-01-01"
},
"size": 875,
"modificationTime": 1643065074000,
"dataChange": true
}
}
{
"add": {
"path": "creation_date=2015-01-02/part-00026-538e1ac6-055e-4e72-9177-63daaaae1f98.c000.snappy.parquet",
"partitionValues": {
"creation_date": "2015-01-02"
},
"size": 875,
"modificationTime": 1643065074000,
"dataChange": true
}
}
{
"add": {
"path": "creation_date=2015-01-02/part-00031-8a03451a-0297-4c43-b64d-56db25807d02.c000.snappy.parquet",
"partitionValues": {
"creation_date": "2015-01-02"
},
"size": 875,
"modificationTime": 1643065072000,
"dataChange": true
}
}
我们继续更新其中一行。Delta Lake提供了一个我们可以使用的合并(merge)操作。我们将使用文档中的语法,它与本地Spark略有不同,因为它创建了一个DeltaTable对象。
from pyspark.sql.functions import lit
# 从inputDF的第一行创建一个新的DataFrame,使用一个不同的creation_date值
updateDF = inputDF.where("id = 100").withColumn("creation_date", lit("2022-01-11"))
from delta.tables import *
from pyspark.sql.functions import *
deltaTable = DeltaTable.forPath(spark, f"s3://{S3_BUCKET_NAME}/tmp/delta/")
deltaTable.alias("oldData") \
.merge(
updateDF.alias("newData"),
"oldData.id = newData.id") \
.whenMatchedUpdate(set = { "creation_date": col("newData.creation_date") }) \
.execute()
有意思的是,现在当我们查看S3时,我们看到一个新的json文件和一个新的parquet文件(记得Hudi和Iceberg都有两个新的parquet文件)。
2022-01-24 23:05:46 1018 tmp/delta/_delta_log/00000000000000000001.json 2022-01-24 23:05:46 875 tmp/delta/creation_date=2022-01-11/part-00000-3f3fd83a-b876-4b6f-8f64-d8a4189392ae.c000.snappy.parquet
如果我们看看这个新的JSON文件,我们会发现一些有意思的事情:
{
"commitInfo": {
"timestamp": 1643065545396,
"operation": "MERGE",
"operationParameters": {
"predicate": "(oldData.`id` = newData.`id`)",
"matchedPredicates": "[{\"actionType\":\"update\"}]",
"notMatchedPredicates": "[]"
},
"readVersion": 0,
"isBlindAppend": false,
"operationMetrics": {
"numTargetRowsCopied": "0",
"numTargetRowsDeleted": "0",
"numTargetFilesAdded": "1",
"executionTimeMs": "4705",
"numTargetRowsInserted": "0",
"scanTimeMs": "3399",
"numTargetRowsUpdated": "1",
"numOutputRows": "1",
"numSourceRows": "1",
"numTargetFilesRemoved": "1",
"rewriteTimeMs": "1265"
}
}
}
{
"remove": {
"path": "creation_date=2015-01-01/part-00005-2e09dbe4-469e-40dc-9b36-833480f6d375.c000.snappy.parquet",
"deletionTimestamp": 1643065545378,
"dataChange": true,
"extendedFileMetadata": true,
"partitionValues": {
"creation_date": "2015-01-01"
},
"size": 875
}
}
{
"add": {
"path": "creation_date=2022-01-11/part-00000-3f3fd83a-b876-4b6f-8f64-d8a4189392ae.c000.snappy.parquet",
"partitionValues": {
"creation_date": "2022-01-11"
},
"size": 875,
"modificationTime": 1643065546000,
"dataChange": true
}
}
除了operationMetrics让我们了解数据如何在“磁盘”上更改之外,我们现在还看到了remove和add操作。在Delta Lake中(我不太清楚为什么会发生这种情况……),每一行都被写入一个单独的.parquet文件! 因此,对于这个数据的第二个版本,更新的行只存在于元数据中,因为它是存储在Parquet文件中的唯一行。我猜这只是因为我的数据集太小了,Spark/Delta Lake的默认分区数导致了这个写配置。
快照
现在我们对每个存储层的语义有了一个很好的了解。让我们再来看看其中一个重要的组成部分,那就是快照!
Hudi
Hudi有一个“时间点”查询的概念,你提供两个提交时间戳的范围,它会显示数据在那个时间点的样子。
# 从表的第一个版本查询数据
readOptions = {
'hoodie.datasource.query.type': 'incremental',
'hoodie.datasource.read.begin.instanttime': '0',
'hoodie.datasource.read.end.instanttime': '20220114003341',
}
incQueryDF = spark.read \
.format('org.apache.hudi') \
.options(**readOptions) \
.load(f"s3://{S3_BUCKET_NAME}/tmp/hudi")
incQueryDF.show()
Iceberg
Iceberg支持一种名为时间旅行的类似机制,可以使用snapshot-id或类似Hudi的as-of-timestamp。
# time travel to 2022-01-27 22:04:00 -0800
df = spark.read \
.option("as-of-timestamp", "1643349840000") \
.format("iceberg") \
.load(ICEBERG_TABLE_NAME)
df.show()
Delta Lake
当然,Delta Lake也可以使用Spark SQL或DataFrames来支持这个功能。与Iceberg类似,可以使用versionAsOf或timestampAsOf。
# time travel to 2022-01-24 23:00
df1 = (
spark.read.format("delta")
.option("timestampAsOf", "2022-01-24 23:00")
.load(f"s3://{S3_BUCKET_NAME}/tmp/delta/")
)
小结
在这篇文章中,我们回顾了Apache Hudi、Apache Iceberg和Delta Lake的基础知识——现代数据湖存储层。所有这些框架都支持一组优化处理基于云的对象存储中的数据的功能,尽管方法略有不同。
