什么是Parquet文件格式,为什么应该使用它?
2022-03-03 19:57:22.0
Apache Parquet是大数据体系结构中的重要组件。自2013年首次引入以来,Apache Parquet作为一种免费和开放源代码的存储格式被广泛采用,用于快速分析查询。AWS在其数据湖导出声明中(2019年),是这样描述Parquet的:“与文本格式相比,在Amazon S3中卸载速度快2倍,存储空间消耗少6倍”。还建议将数据转换为Parquet或ORC等柱状格式,以提高Amazon Athena的性能。很明显,在处理数据湖时,Apache Parquet在系统性能中扮演着重要的角色。那么,Parquet到底是什么? 它为什么对大数据存储和分析这么重要?
基础知识:什么是Apache Parquet?
Apache Parquet是一种文件格式,旨在支持对复杂数据的快速数据处理,具有以下几个显著特征:
1. 列式存储:与CSV或Avro等基于行的格式不同,Apache Parquet是面向列的——这意味着每个表列的值是挨着存储的,而不是每个记录的值:

2. 开源:Parquet在Apache Hadoop许可下是免费使用和开源的,并且与大多数Hadoop数据处理框架兼容。引用项目官网的话,“Apache Parquet……适用于任何项目……无论选择数据处理框架、数据模型或编程语言。”
3.自描述:除了数据之外,Parquet文件还包含元数据,包括模式和结构。每个文件都存储数据和用于访问每个记录的标准——这使得编写、存储和读取Parquet文件的服务更容易解耦。
Apache Parquet列式存储的优势
在存储和分析大量数据时,Apache Parquet文件格式的上述特征带来了几个明显的好处:
压缩
文件压缩是将文件缩小的过程。在Parquet中,压缩是逐列执行的,并构建它来支持灵活的压缩选项和每个数据类型可扩展的编码模式——例如,可以使用不同的编码来压缩整数和字符串数据。
Parquet数据可以使用以下编码方法进行压缩:
- 字典编码:对于具有少量唯一值的数据,这是自动和动态启用的。
- 位打包:整数的存储通常用每个整数专用的32或64位来完成。这允许更有效地存储较小的整数。
- 运行长度编码(Run length encoding,RLE):当同一个值多次出现时,一个值只存储一次,同时存储出现的次数。Parquet实现了位打包和RLE的组合版本,其中基于它的编码开关产生了最好的压缩结果。
性能
与基于行格式(如CSV)的文件格式不同,Parquet的性能得到了优化。在基于parquet的文件系统上运行查询时,可以快速聚焦相关的数据。此外,扫描的数据量将大大减少,从而减少I/O访问量。为了理解这一点,让我们更深入地了解一下Parquet文件的结构。
如上所述,Parquet是一种自描述的格式,因此每个文件都包含数据和元数据。Parquet文件由row groups(行组)、header和footer组成。每个row group(行组)包含来自相同列的数据。相同的列存储在每个row group(行组)中:
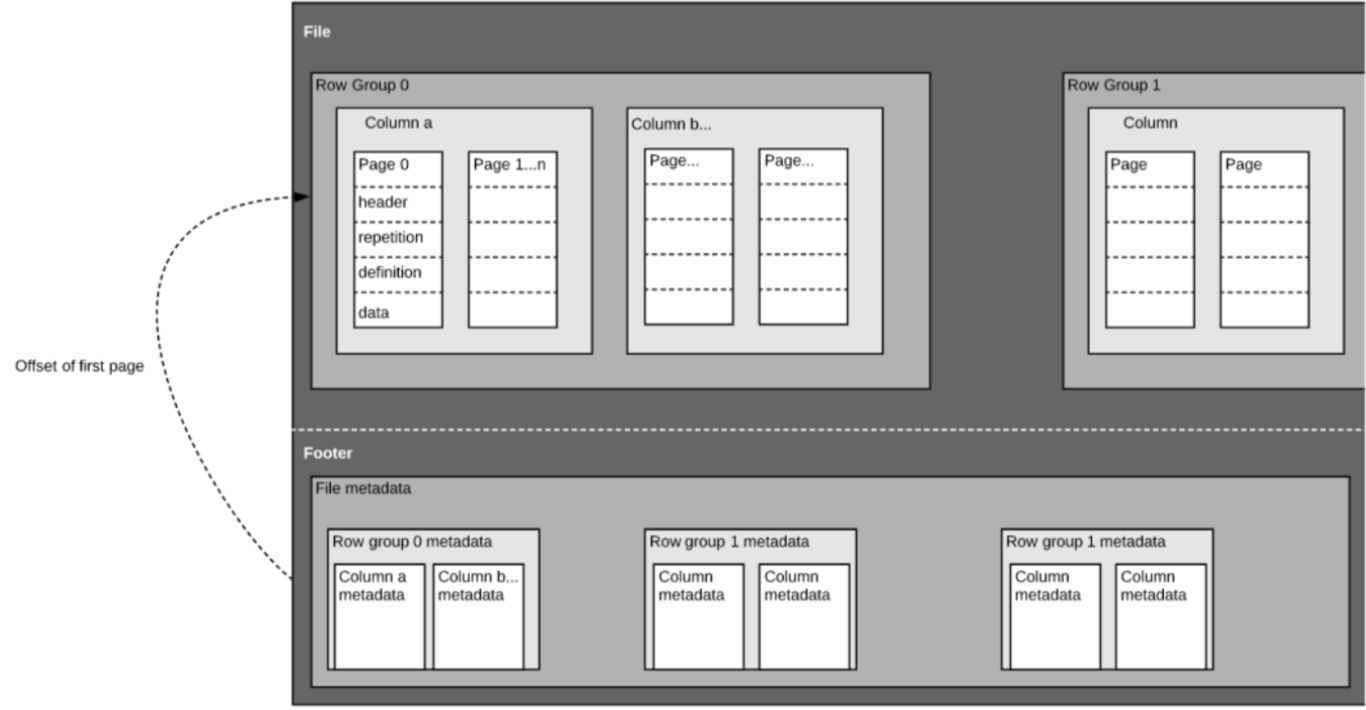
该结构在快速查询性能和低I/O(最大限度地减少扫描的数据量)方面进行了很好的优化。例如,如果有一个有1000列的表,我们通常只会使用列的一小部分进行查询。使用Parquet文件将使我们能够只获取所需的列及其值,在内存中加载这些列并回答查询。如果使用像CSV这样的基于行的文件格式,则必须将整个表加载到内存中,从而导致I/O增加和性能下降。
模式演变
当使用像Parquet这样的柱状文件格式时,用户可以从一个简单的模式开始,然后根据需要逐渐向模式添加更多的列。这样,用户最终可能会得到多个具有不同但相互兼容的模式的Parquet文件。在这些情况下,Parquet支持这些文件之间的自动模式合并。
开源和非专有的
Apache Parquet是开源的Apache Hadoop生态系统的一部分。围绕它的开发工作是积极的,强大的用户和开发人员社区正在不断地改进和维护它。
与许多现代高性能数据库使用的专有文件格式相比,以开放格式存储数据意味着我们避免了厂商锁定,并增加了灵活性。这意味着您可以在相同的数据湖体系结构中使用各种查询引擎,而不是绑定到特定的数据库供应商。
用于分析查询的面向列的存储与基于行的存储对比
数据通常以行形式生成,更容易概念化。我们习惯于从Excel电子表格的角度来思考问题,在Excel电子表格中,我们可以将与特定记录相关的所有数据放在一个整齐有序的行中。然而,对于大规模的分析查询,列存储在成本和性能方面具有显著的优势。
像日志和事件流这样的复杂数据需要表示为包含数百或数千列和数百万行的表。将此表存储为基于行格式(如CSV)意味着:
- 由于需要扫描更多的数据,查询将花费更长的时间运行,而不是只查询我们需要回答查询问题的列的子集(这通常需要基于维度或类别进行聚合)
- 由于CSV压缩的效率不如Parquet高,因此存储成本将更高。
柱状格式提供了更好的压缩和改进的开箱即用的性能,并允许您垂直地逐列查询数据。
Apache Parquet应用场景 - 什么时候应该使用它?
下面是列出的一些应该在Parquet中存储数据的建议和提示。
- 当在处理大量的数据时。Parquet是为性能和有效的压缩而构建的。各种基准测试比较了Parquet上的SQL查询与Avro或CSV等格式的处理时间,发现查询Parquet可以显著加快查询速度。
- 当完整数据集有许多列,但只需要访问一个子集时。由于正在记录的业务数据越来越复杂,我们可能会发现,现在需要为每个数据事件捕获100多个字段,而不是为每个数据事件收集20个字段。虽然这些数据很容易存储在数据湖中,但如果以基于行的格式存储,查询它将需要扫描大量的数据。Parquet的柱状和自描述特性允许我们只拉取出回答特定查询所需的列,从而减少了处理的数据量。
- 当希望多个服务使用来自对象存储的相同数据时。虽然Oracle和Snowflake等数据库供应商更喜欢使用只有他们的工具才能读取的专有格式存储数据,但现代数据体系结构倾向于将存储与计算解耦。如果想使用多个分析服务来回答不同的应用场景,那么应该在Parquet中存储数据。
