赛题模拟实现-数据采集与实时计算
任务内容:
启动业务系统,按照要求使用Flume将用户操作日志采集并存入Kafka中并使用Flink、Scala消费Kafka中的数据将其进行聚合计算出商城在线人数,将结果存入Redis中,并统计该电商系统的UV与PV将结果存入MySQL中。
实现原理:
从前面的任务剖析部分可以知道,Flink采用的版本是1.10.2。整个任务实现的架构和流程如下图:

实现过程
1)在IDEA中创建一个Flink Maven项目:Flink102Example。
参考教程:使用IntelliJ IDEA+Maven开发Flink项目。
2)完成第一个任务:“使用Flume采集某电商系统用户操作日志存入Kafka中”。
2.1)技术参考:
2.2)在$FLUME_HOME/conf/目录下,创建一个配置文件file-to-kafka.conf,并编辑内容如下:
# file-to-kafka.conf # 命名这个agent的组件 agent1.sources = r1 agent1.sinks = sk1 agent1.channels = ch1 # 描述和配置source,注意监视的路径 agent1.sources.r1.type = spooldir agent1.sources.r1.spoolDir=/home/hduser/data/flink/logdata # 使用一个在内存中缓冲事件的channel agent1.channels.ch1.type = memory agent1.channels.ch1.capacity = 10000 agent1.channels.ch1.transactionCapacity = 100 # 描述sink agent1.sinks.sk1.type = org.apache.flume.sink.kafka.KafkaSink agent1.sinks.sk1.kafka.topic = mylog agent1.sinks.sk1.kafka.bootstrap.servers = localhost:9092 agent1.sinks.sk1.kafka.flumeBatchSize = 20 agent1.sinks.sk1.kafka.producer.acks = 1 agent1.sinks.sk1.kafka.producer.linger.ms = 10 agent1.sinks.sk1.kafka.producer.compression.type = snappy # 将source和sink绑定到channel agent1.sources.r1.channels = ch1 agent1.sinks.sk1.channel = ch1
2.3)启动Zookeeper。打开一个终端窗口,执行如下命令:
# 切换到Kafka的安装目录 $ cd ~/bigdata/kafka_2.12-2.4.1 $ ./bin/zookeeper-server-start.sh config/zookeeper.properties
2.4)启动Kafka。打开另一个终端窗口,执行如下命令:
# 切换到Kafka的安装目录 $ cd ~/bigdata/kafka_2.12-2.4.1 $ ./bin/kafka-server-start.sh config/server.properties
2.5)在Kafka中创建主题user-behavior。打开另一个终端窗口,执行如下命令:
# 切换到Kafka的安装目录 $ cd ~/bigdata/kafka_2.12-2.4.1 # 创建一个名为mylog的topic $ ./bin/kafka-topics.sh --create \ --zookeeper localhost:2181 \ --replication-factor 1 \ --partitions 1 \ --topic user-behavior
2.6)将用户操作日志文件(例如,UserBehavior.csv)拷贝到系统的指定路径下,比如/home/hduser/data/flink/logdata/目录下。
2.7)启动Flume Agent。在终端窗口中,执行如下命令:
# 切换到Flume安装目录 $ cd ~/bigdata/flume-1.9.0 $ ./bin/flume-ng agent \ -n agent1 \ -c ./conf -f ./conf/file-to-kafka.conf \ -Dflume.root.logger=INFO,console
2.8)运行Kafka自带的消费者脚本,让其监听user-behavior主题。打开另一个终端窗口,执行下面的命令:
# 切换到Kafka的安装目录
$ cd ~/bigdata/kafka_2.12-2.4.1
$ ./bin/kafka-console-consumer.sh \
--bootstrap-server localhost:9092 \
--topic user-behavior \
--from-beginning
注意观察Kafka消费者脚本运行窗口,会看到Flume已经快速而准确地把这个日志文件发送给了Kafka,并且消费者脚本程序及时地消费并输出了该日志文件的内容。
3) 完成第二个任务:“使用Flink消费Kafka中的数据”。
代码实现:
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010
import java.util.Properties
/**
* 完成第二个任务:“使用Flink消费Kafka中的数据”
*/
object ConsumeKafkaDemo {
def main(args: Array[String]) {
// 设置流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 设置事件时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 设置并行度
env.setParallelism(1)
// kafka连接属性配置// kafka连接属性配置
val props = new Properties()
props.setProperty("bootstrap.servers", "localhost:9092")
props.setProperty("group.id", "my-group")
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
// 定义Kafka消费者
val myConsumer = new FlinkKafkaConsumer010[String]("user-behavior",new SimpleStringSchema(),props)
myConsumer.setStartFromEarliest() // 尽可能从最早的记录开始
// myConsumer.setStartFromLatest() // 从最新的记录开始
// myConsumer.setStartFromTimestamp(...) // 从指定的时间戳(毫秒)开始
// myConsumer.setStartFromGroupOffsets() // 默认的行为
// 读取数据源并在控制台输出内容
env
.addSource(myConsumer) // 指定Kafka数据源
.print() // 输出到控制台
// 触发流程序执行
env.execute("Consume Kafka Topic")
}
}
观察控制台,可以看到类似如下的输出内容:
4) 完成第三个任务:“聚合计算出系统在线人数并将结果存入Redis中”。
日志数据样例:(详细数据集说明在下载的源码包中)
543462,1715,1464116,pv,1511658000 662867,2244074,1575622,pv,1511658000 561558,3611281,965809,pv,1511658000 894923,3076029,1879194,pv,1511658000 834377,4541270,3738615,pv,1511658000
字段说明:
| 列名称 | 说明 |
|---|---|
| 用户ID | 整数类型,序列化后的用户ID |
| 商品ID | 整数类型,序列化后的商品ID |
| 商品类目ID | 整数类型,序列化后的商品所属类目ID |
| 行为类型 | 字符串,枚举类型,包括('pv', 'buy', 'cart', 'fav') |
| 时间戳 | 行为发生的时间戳 |
实现思路:每个UserId代表一个单独的用户。计算在线人数,也就是有多少个唯一ID。
实现方法:滚动窗口 + 窗口函数。
实现代码:
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.AssignerWithPunctuatedWatermarks
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessAllWindowFunction
import org.apache.flink.streaming.api.watermark.Watermark
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010
import org.apache.flink.streaming.connectors.redis.RedisSink
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig
import org.apache.flink.streaming.connectors.redis.common.mapper._
import org.apache.flink.util.Collector
import java.text.SimpleDateFormat
import java.util.{Date, Properties}
import scala.collection.mutable
object OnlineUsers {
// 输入事件类型 [用户id, 1]
case class InputEvent(userid: Int, count: Int)
// 输出事件类型 [时间戳,在线人数]
case class OutputEvent(winend:Long, count:Int)
def main(args: Array[String]) {
// 设置流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 设置事件时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 设置并行度
env.setParallelism(1)
// kafka连接属性配置// kafka连接属性配置
val props = new Properties()
props.setProperty("bootstrap.servers", "localhost:9092")
props.setProperty("group.id", "my-group")
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
// 定义Kafka消费者
val myConsumer = new FlinkKafkaConsumer010[String]("user-behavior",new SimpleStringSchema(),props)
myConsumer.setStartFromEarliest() // 尽可能从最早的记录开始
// myConsumer.setStartFromLatest() // 从最新的记录开始
// myConsumer.setStartFromTimestamp(...) // 从指定的时间戳(毫秒)开始
// myConsumer.setStartFromGroupOffsets() // 默认的行为
// 分配水印
myConsumer.assignTimestampsAndWatermarks(
new AssignerWithPunctuatedWatermarks[String] {
// 分配水印
override def checkAndGetNextWatermark(t: String, l: Long): Watermark = {
if (null != t && t.contains(",")) {
val parts = t.split(",")
val watermark = new Watermark(parts(4).toLong * 1000)
watermark
}else{
null
}
}
// 分配时间戳
override def extractTimestamp(t: String, l: Long): Long = {
if (null != t && t.contains(",")) {
val parts = t.split(",")
parts(4).toLong * 1000
}else{
0
}
}
})
// 定义redis sink的配置 (默认端口号6379)
val conf = new FlinkJedisPoolConfig.Builder().setHost("localhost").setPort(6379).build()
val online = env
.addSource(myConsumer) // 指定Kafka数据源
.map { _.split(",") } // 先分割每一行
.map(arr => InputEvent(arr(0).toInt, 1)) // 转换为InputEvent
.windowAll(TumblingEventTimeWindows.of(Time.hours(1))) // 1小时滚动窗口
.process(new MyProcessWindowFunction()) // 窗口处理函数
// 输出到控制台
online.print()
// 写出到Redis
online.addSink(new RedisSink[OutputEvent](conf, new RedisExampleMapper))
// 触发流程序执行
env.execute("count online")
}
// 自定义窗口处理函数
class MyProcessWindowFunction extends ProcessAllWindowFunction[InputEvent,OutputEvent,TimeWindow]{
override def process(context: Context,
elements: Iterable[InputEvent],
out: Collector[OutputEvent]): Unit = {
val usersSet = mutable.Set[Int]() // 注意,这是个可变集合
for(e <- elements){
usersSet.add(e.userid) // 把用户id添加到Set集合中
}
// 写出(时间戳,在线人数)
out.collect(OutputEvent(context.window.getEnd, usersSet.size))
}
}
// redisMap接口,设置key和value
class RedisExampleMapper extends RedisMapper[OutputEvent]{
// getCommandDescription:设置数据使用的数据结构 HashSet 并设置key的名称
override def getCommandDescription: RedisCommandDescription = {
// RedisCommand.SET 指定存储类型
new RedisCommandDescription(RedisCommand.SET, "online")
}
/**
* 获取 value值 value的数据是键值对
* @param data
* @return
*/
//指定key
override def getKeyFromData(t: OutputEvent): String = "online"
// 指定value
override def getValueFromData(t: OutputEvent): String = tranTimeToString(t.winend) + ": " + t.count
// 时间戳转日期表示格式
def tranTimeToString(ts:Long) :String={
val fm = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
val tim = fm.format(new Date(ts))
tim
}
}
}
执行步骤:
1)启动Zookeeper。打开一个终端窗口,执行如下命令:
# 切换到Kafka的安装目录 $ cd ~/bigdata/kafka_2.12-2.4.1 $ ./bin/zookeeper-server-start.sh config/zookeeper.properties
2)启动Kafka。打开另一个终端窗口,执行如下命令:
# 切换到Kafka的安装目录 $ cd ~/bigdata/kafka_2.12-2.4.1 $ ./bin/kafka-server-start.sh config/server.properties
3)启动Redis Server。再打开一个终端窗口,执行如下命令:
# 切换到Redis的安装目录 $ cd ~/bigdata/redis-6.2.6 $ ./bin/redis-server ./conf/redis.conf
4)运行上面编写的流执行程序(相当于Kafka的消费者程序),在控制台应当可以看到输出的在线人数统计结果。如下图所示:
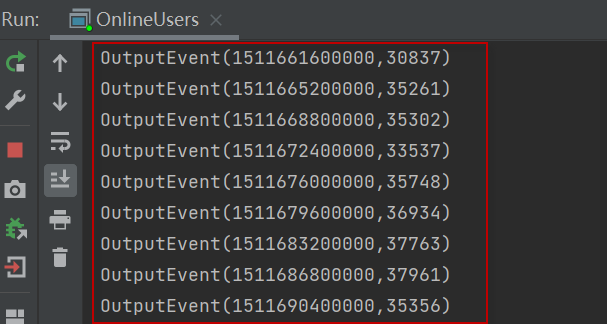
5)运行Redis cli,查看写入的结果。在一个终端窗口,执行下面的命令:
# 切换到Redis的安装目录 $ cd ~/bigdata/redis-6.2.6 $ ./bin/redis-cli
然后在redis命令行下,执行查询:
redis> get online
应当可以看到写入的值。如下:

5) 完成第四个任务:“统计系统的UV与PV并存入MySQL中”。
- PV(访问量):即Page View, 即页面浏览量或点击量,用户每次刷新即被计算一次。
- UV(独立访客):即Unique Visitor,访问网站的一台电脑客户端为一个访客。
日志数据样例:
543462,1715,1464116,pv,1511658000 662867,2244074,1575622,pv,1511658000 561558,3611281,965809,pv,1511658000 894923,3076029,1879194,pv,1511658000 834377,4541270,3738615,pv,1511658000
实现思路:滚动窗口 + 窗口函数。其中uv要去重,pv要累加。
实现代码如下:
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.AssignerWithPunctuatedWatermarks
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.scala.function.ProcessAllWindowFunction
import org.apache.flink.streaming.api.watermark.Watermark
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010
import org.apache.flink.util.Collector
import java.sql.{Connection, DriverManager, PreparedStatement}
import java.util.Properties
import scala.collection.mutable
object PvAndUv {
// 输入事件类型
case class InputEvent(userid: Int, behavior:String, count: Int)
// 输出事件类型
case class OutputEvent(winend:Long, uv:Int, pv:Int)
def main(args: Array[String]) {
// 设置流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 设置事件时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 设置并行度
env.setParallelism(1)
// kafka连接属性配置
val props = new Properties()
props.setProperty("bootstrap.servers", "localhost:9092")
props.setProperty("group.id", "my-group")
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
// 定义Kafka消费者
val myConsumer = new FlinkKafkaConsumer010[String]("user-behavior",new SimpleStringSchema(),props)
myConsumer.setStartFromEarliest() // 尽可能从最早的记录开始
// myConsumer.setStartFromLatest() // 从最新的记录开始
// myConsumer.setStartFromTimestamp(...) // 从指定的时间戳(毫秒)开始
// myConsumer.setStartFromGroupOffsets() // 默认的行为
// 分配水印
myConsumer.assignTimestampsAndWatermarks(
new AssignerWithPunctuatedWatermarks[String] {
// 分配水印
override def checkAndGetNextWatermark(t: String, l: Long): Watermark = {
if (null != t && t.contains(",")) {
val parts = t.split(",")
val watermark = new Watermark(parts(4).toLong * 1000)
watermark
}else{
null
}
}
// 分配时间戳
override def extractTimestamp(t: String, l: Long): Long = {
if (null != t && t.contains(",")) {
val parts = t.split(",")
parts(4).toLong * 1000
}else{
0
}
}
})
val streamResult = env
.addSource(myConsumer) // 指定Kafka数据源
.map { _.split(",") } // 先分割每一行
.map(arr => InputEvent(arr(0).toInt,arr(3), 1)) // 转换为InputEvent
.windowAll(TumblingEventTimeWindows.of(Time.hours(1))) // 1小时滚动窗口
.process(new MyProcessWindowFunction())
streamResult.print()
// Flink-1.10及以前,没有提供JDBC Sink, 使用自定义的Sink
streamResult.addSink(new MyJDBCSink())
// 触发流程序执行
env.execute("count uv and pv")
}
// 自定义窗口处理函数
class MyProcessWindowFunction extends ProcessAllWindowFunction[InputEvent,OutputEvent,TimeWindow]{
override def process(context: Context,
elements: Iterable[InputEvent],
out: Collector[OutputEvent]): Unit = {
val usersSet = mutable.Set[Int]() // 注意,这是个可变集合
var pvCount = 0 // 统计pv数
for(e <- elements){
usersSet.add(e.userid) // uv要去重
if(e.behavior=="pv"){
pvCount += 1 // pv要累加
}
}
// 发送到下游
out.collect(OutputEvent(context.window.getEnd, usersSet.size, pvCount))
}
}
//指定Sink的范型People
class MyJDBCSink() extends RichSinkFunction[OutputEvent] {
// 定义mysql数据库连接url和驱动程序及账号、密码
val url = "jdbc:mysql://localhost:3306/test?characterEncoding=UTF-8&useSSL=false"
val driver = "com.mysql.jdbc.Driver"
val username = "root"
val userpwd = "admin"
//定义SQL的连接、预编译器,给定初始值占位符
var conn: Connection = _
var stmt: PreparedStatement = _
/**
* 重写open方法:加载驱动,建立连接,预编译SQL语句
* 先于invoker方法用,仅执行一次
* @param parameters
*/
override def open(parameters: Configuration): Unit = {
super.open(parameters)
Class.forName(driver) // 加载驱动程序
conn = DriverManager.getConnection(url, username, userpwd) // 连接数据库
// 执行SQL语句
val sql = "insert into uv_pv_tb (ts, uv, pv) values (?, ?, ?)"
stmt = conn.prepareStatement(sql)
}
/**
* 调用方法,调用逻辑都是在里面,数据类型、格式组合都是在里面进行
* 编写
* @param value
* @param context
*/
override def invoke(value: OutputEvent, context: SinkFunction.Context[_]): Unit = {
//执行update SQL
stmt.setLong(1, value.winend)
stmt.setInt(2, value.uv)
stmt.setInt(3, value.pv)
stmt.executeUpdate
}
/**
* close方法用来关闭资源,清理工作,类似于Finally
*/
override def close(): Unit = {
super.close()
if (stmt != null) stmt.close()
if (conn != null) conn.close()
}
}
}
执行步骤:
1) 在MySQL数据库中创建数据表:
create table uv_pv_tb(
ts bigint,
uv int,
pv int
);
2)启动Zookeeper。打开一个终端窗口,执行如下命令:
# 切换到Kafka的安装目录 $ cd ~/bigdata/kafka_2.12-2.4.1 $ ./bin/zookeeper-server-start.sh config/zookeeper.properties
3)启动Kafka。打开另一个终端窗口,执行如下命令:
# 切换到Kafka的安装目录 $ cd ~/bigdata/kafka_2.12-2.4.1 $ ./bin/kafka-server-start.sh config/server.properties
4)运行上面编写的流执行程序(相当于Kafka的消费者程序),在控制台应当可以看到输出的uv和pv统计结果。如下图所示:
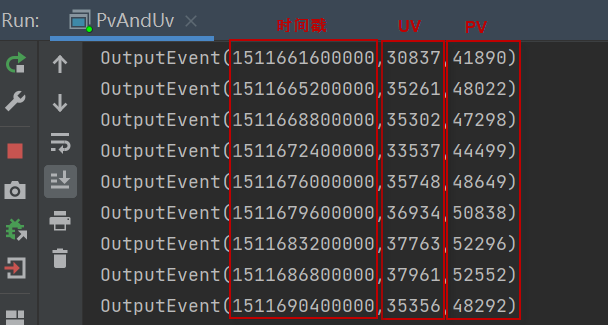
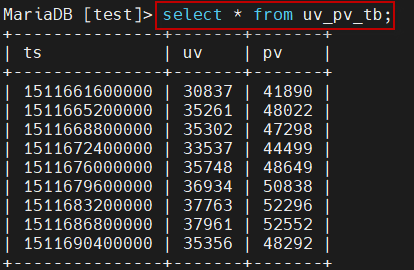
5)在MySQL中执行如下的查询语句,查看uv_pv_tb表中的内容:
mysql> select * from uv_pv_tb;
这时应当可以看到写入的uv和pv值:
至此,数据采集与实时计算任务已经全部完成了!