赛题模拟实现-离线数据抽取
数据准备
这里使用的是Kaggle上的公共数据集,来自巴西olist商店电子商务订单。该数据集提供 2016 年至 2018 年在巴西多个市场下订单的 10 万份信息。其功能允许从多个维度查看订单:从订单状态、价格、付款和货运性能到客户位置、产品属性以及客户撰写的最后评论。 数据说明。
我们选取了其中4张表,E-R模型图如下:

对这4张表分别说明如下:
- orders:订单表。每个订单包含多个商品项。
- order_items:订单商品项表。
- customers:客户信息表。
- products:商品信息表。
因为数据集本身是文件性质,而竞赛任务中要求是从MySQL数据源抽取数据,因此我们准备一个MySQL数据源:将Olist上述四张表导入到MySQL中。请按以下说明导入:
1)先在MySQL中创建数据库olist:
mysql> create database olist;
2)然后执行以下命令导入数据库(在终端窗口执行):
$ mysql -uroot -p olist < olist.sql
3)测试导入是否成功:
mysql> use olist; mysql> select * from products limit 5;
实现任务二:离线数据抽取
具体内容:
按照要求使用Scala语言完成特定函数的编写,使用Spark抽取MySQL指定数据表中的新增的数据到ODS层的指定的分区表中。
- (1) 使用Spark抽取MySQL指定数据表中的新增的商品数据到ODS层的指定的分区表中;
- (2) 使用Spark抽取MySQL指定数据表中的新增的用户数据到ODS层的指定的分区表中;
- (3) 使用Spark抽取MySQL指定数据表中的新增的订单数据到ODS层的指定的分区表中;
实现原理:
什么是ODS层?这是一个数据仓库的概念,指的是数据运营层ODS(Operation Data Store),是数据准备区,也称为贴源层。
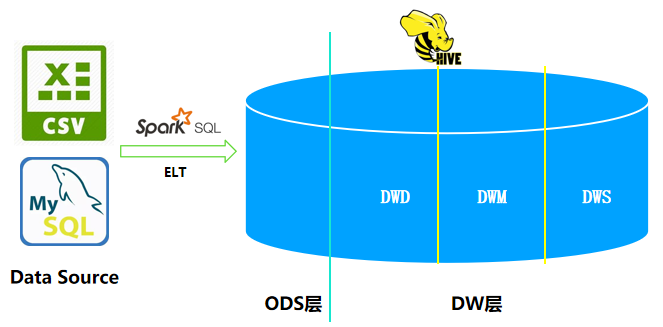
Spark ETL过程:
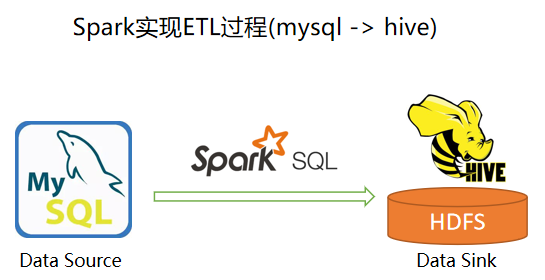
实现过程:
1)在IDEA中创建一个Maven项目。 可参考小白学苑的教程:使用IntelliJ IDEA开发Spark Maven应用程序。
2)新建一个EtlUtil工具类,封装从MySQL中抽取数据的方法函数以及将数据加载到Hive的方法函数。实现代码如下:
package com.bigdataplay2021
import org.apache.spark.sql._
import java.util.Properties
// 定义工具类
object EtlUtil {
// extract from mysql
/**
* @param spark SparkSession实例
* @param jdbcMap 要加载的JDBC配置项
*
* @return 返回一个DataFrame(Dataset[Row])
*
*/
def extractFromJDBC(spark: SparkSession, jdbcMap:Map[String,String]): Dataset[Row] = {
// 读取JDBC数据源,创建DataFrame
val df = spark
.read
.format("jdbc")
.options(jdbcMap)
.load()
// 返回
df
}
// load to hive
/**
* @param spark
* @param df 要装载到Hive中的DataFrame
* @param db 要装载到的Hive数据库
* @param tb 要装载到的Hive ODS表
* @param partitionColumn 指定分区列
*
* @return unit
*/
def loadToHive(spark: SparkSession,
df:Dataset[Row],
db:String,
tb:String,
partitionColumn: Option[String] = None) = {
spark.sql(s"use $db") // 打开指定数据库,这里使用了字符串插值
// 有的表需要分区,有的不需要。这里使用模式匹配来分别处理
partitionColumn match{
case Some(column) =>
df.write
.format("parquet")
.mode(SaveMode.Overwrite) // 覆盖
.partitionBy(column) // 指定分区
.saveAsTable(tb)
case None =>
df.write
.format("parquet")
.mode(SaveMode.Overwrite) // 覆盖
.saveAsTable(tb) // saveAsTable()方法:会将DataFrame数据保存到Hive表中
}
}
// 定义一个ELT方法,包含extract + load
def eltFromJDBCToHive(spark: SparkSession,
jdbcMap:Map[String,String],
hiveMap: Map[String,String]) = {
// extract from jdbc
val df = extractFromJDBC(spark, jdbcMap)
// load to hive
val database = hiveMap("db") // 数据库
val table = hiveMap("tb") // 数据表
loadToHive(spark, df, database, table, None)
}
// 定义一个函数,用来将分析结果导出到mysql中
/**
*
* @param db 目标数据表
* @param df 分析结果集
*/
def exportToMysql(df:Dataset[Row], tb:String) = {
// 数据库连接url。注意:这里写出的是mysql的olist数据库
val DB_URL= "jdbc:mysql://localhost:3306/olist?useSSL=false"
// 下面创建一个prop 变量用来保存JDBC 连接参数
val props = new Properties()
props.put("user", "root") // 表示用户名是root
props.put("password", "admin") // 表示密码是hadoop
props.put("driver","com.mysql.jdbc.Driver") // 表示驱动程序
df.write.mode(SaveMode.Append).jdbc(DB_URL, tb, props)
}
}
3)新建一个执行ETL抽取任务的作业类,代码如下:
package com.bigdataplay2021
import org.apache.spark.sql.SparkSession
object EtlJob {
def main(args: Array[String]): Unit = {
// 在windows下开发时设置
System.setProperty("HADOOP_USER_NAME", "hduser")
// 创建SparkSession
val spark = SparkSession.builder()
.master("local[*]")
.appName("bigdata play")
.enableHiveSupport()
.getOrCreate()
// 打开Hive动态分区的标志
spark.sqlContext.setConf("hive.exec.dynamic.partition", "true")
spark.sqlContext.setConf("hive.exec.dynamic.partition.mode", "nonstrict")
// 1)抽取客户数据到ODS层的指定的维表中
etlCustomersDim(spark)
// 2)抽取商品数据到ODS层的指定的维表中
etlProductsDim(spark)
// 3)抽取订单数据到ODS层的指定的分区表中
etlOrdersODS(spark)
// 4)抽取订单项数据到ODS层的指定的分区表中
etlOrderItemsODS(spark)
}
// 1)抽取客户数据到ODS层的指定的维表中
def etlCustomersDim(spark: SparkSession) = {
// 数据库连接url
val DB_URL= "jdbc:mysql://localhost:3306/olist?useSSL=false"
val jdbcMap = Map(
"url" -> DB_URL, // jdbc url
"dbtable" -> "customers", // 要读取的数据表
"user" -> "root", // mysql账号
"password" -> "admin" // mysql密码
)
// 定义ODS配置
val hiveOptions = Map("db" -> "olistdb", "tb" -> "dim_customers")
// ELT
EtlUtil.eltFromJDBCToHive(spark, jdbcMap, hiveOptions)
// 测试
spark.table("olistdb.dim_customers").show(5)
}
// 2)抽取商品数据到ODS层的指定的维表中
def etlProductsDim(spark: SparkSession) = {
// 数据库连接url
val DB_URL= "jdbc:mysql://localhost:3306/olist?useSSL=false"
val jdbcMap = Map(
"url" -> DB_URL, // jdbc url
"dbtable" -> "products", // 要读取的数据表
"user" -> "root", // mysql账号
"password" -> "admin" // mysql密码
)
// 定义ODS配置
val hiveOptions = Map("db" -> "olistdb", "tb" -> "dim_products")
// ELT
EtlUtil.eltFromJDBCToHive(spark, jdbcMap, hiveOptions)
// 测试
spark.table("olistdb.dim_products").show(5)
}
// 3)抽取订单数据到ODS层的指定的分区表中 - 事实表,分区存储?
def etlOrdersODS(spark: SparkSession) = {
val DB_URL= "jdbc:mysql://localhost:3306/olist?useSSL=false" // 数据库连接url
val jdbcMap = Map(
"url" -> DB_URL, // jdbc url
"dbtable" -> "orders", // 要读取的数据表
"user" -> "root", // mysql账号
"password" -> "admin" // mysql密码
)
// 定义ODS配置
val hiveOptions = Map("db" -> "olistdb", "tb" -> "ods_orders")
// 如果分区的话
// val hiveOptions = Map("db" -> "olistdb", "tb" -> "ods_orders", "partitionColumn" -> "order_estimated_delivery_date")
// ELT
EtlUtil.eltFromJDBCToHive(spark, jdbcMap, hiveOptions)
// 测试
spark.table("olistdb.ods_orders").show(5)
}
// 4)抽取订单项数据到ODS层的指定的分区表中 - 事实表,分区存储?
def etlOrderItemsODS(spark: SparkSession) = {
val DB_URL= "jdbc:mysql://localhost:3306/olist?useSSL=false" // 数据库连接url
val jdbcMap = Map(
"url" -> DB_URL, // jdbc url
"dbtable" -> "order_items", // 要读取的数据表
"user" -> "root", // mysql账号
"password" -> "admin" // mysql密码
)
// 定义ODS配置
val hiveOptions = Map("db" -> "olistdb", "tb" -> "ods_order_items")
// 如果分区存储的话
// val hiveOptions = Map("db" -> "olistdb", "tb" -> "ods_order_items", "partitionColumn" -> "order_item_id")
// ELT
EtlUtil.eltFromJDBCToHive(spark, jdbcMap, hiveOptions)
// 测试
spark.table("olistdb.ods_order_items").show(5)
}
}
4)4)项目打包。
将项目打包jar包以便部署。打包命令(在IDEA Terminal终端窗口中执行):
$ mvn clean package
如下图所示:
5)5)项目部署。
首先启动Hive Metastore服务,并保持运行(不要关闭):
$ hive --service metastore
将项目部署到Spark上运行,部署命令:
$ spark-submit --class com.bigdataplay2021.EtlJob hellospark-1.0-SNAPSHOT.jar注:以上代码和操作中,涉及到操作的目录路径、包名、类名等,可自行修改保持正确即可。