电商大数据分析案例(Hadoop+Hive+Spark+Azkaban+Spring MVC+ECharts)
项目描述
某著名电商平台双十一美妆销售数据分析。由于是真实的商业数据,所以做了脱敏处理,数据集中对店名的引用被处理为产品的品牌名以保护店家隐私。。
通过对该平台双十一美妆销售数据的品牌、销量、热度等特征的分析(平台视角和用户视角),尝试探索以下问题:
- 双十一期间,最受消费者青睐的产品或品牌是哪些?
- 双十一期间,美妆行业各品类的销售情况?
- 双十一期间,消费高峰何时出现?
- 双十一期间,客户的评论数对销量的影响?
- ......
项目架构
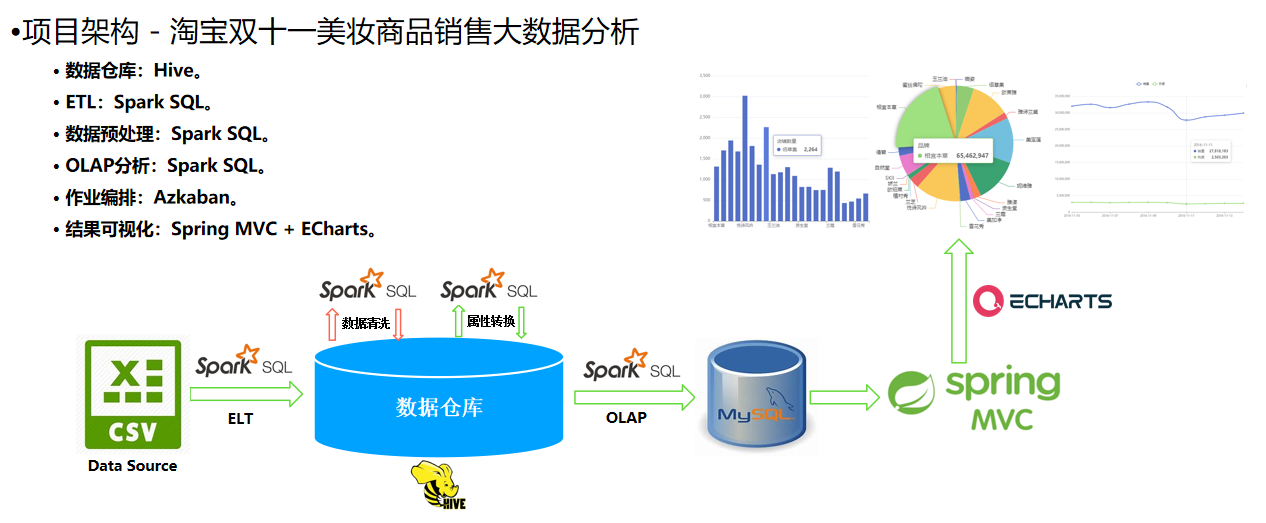
项目流程
项目流程说明如下:
- 1. 数据集:使用Spark ETL技术,将数据抽取到Hive数据仓库ODS层;
- 2. 大数据清洗:使用Spark SQL进行数据清洗,包括数据去重和错误数据处理;
- 3. 大数据属性转换与整理:使用Spark SQL进行数据属性预处理,包括属性转换与抽取、属性选择等;
- 4. 大数据分析:使用Spark SQL平台角度和用户角度分别进行分析,并使用Spark ETL技术将分析结果写出到MySQL数据库中;
- 5. 大数据可视化:使用Spring MVC + Apache ECharts展示分析结果。
注:本项目使用了分词处理技术以抽取商品分类属性。
适用对象
本项目适合以下人员学习使用:
- 已有Hadoop和Spark基础,需要掌握大数据完整开发和分析流程、积累大数据项目经验;
- 大数据毕业设计项目。
项目实施过程
本项目使用Hive作业数据仓库,使用Spark SQL开发数据处理管道,包括ETL、数据清洗和数据预处理,并使用Spark SQL作为OLAP引擎。大数据分析结果写出到MySQL数据库中,最后使用Spring MVC和Apache ECharts开发Web应用程序,对分析结果进行可视化展示。整体项目实施过程如下:
1. 数据ETL使用Spark SQL开发ETL作业,将某电商平台双十一美妆销售数据抽取并加载到Hive数据仓库的ODS层。
2. 大数据清洗和预处理使用Spark对大数据进行清洗,包括去重、错误数据处理、空值处理、属性转换、属性提取等数据预处理任务。其中比较难处理的(难点及亮点)是对美妆商品抽取主类别和子类别属性。这里我们在Spark平台上使用了结巴分词工具包来抽取这两个属性。
3. 大数据分析使用Spark SQL从多个维度对整理后的销售数据集进行分析。在项目实施过程中,我们先使用Zeppelin NoteBook执行交互式探索和分析,然后将实现过程使用IntellIJ IDEA进行项目重构。
4. 作业部署和执行项目使用Maven打jar包,使用Azkaban进行作业编排(当然是可选的,也可省略作业编排,手工依次执行),并部署到Spark集群上执行。最终分析结果写出到MySQL数据库中。
5. 大数据可视化使用IntellIJ IDEA开发Spring MVC项目,使用ECharts作为可视化组件,展示分析结果。
以上实现各步骤的具体实现,请下载项目源码参考。
如果您是会员,并申请了终身会员权限,可下载本项目所有源码和测试数据。
您还未登录!(正式会员登录后可下载)
项目视频讲解
请点击下方链接,选择要播放的讲解视频。(注:正式用户登录方可观看全部项目视频)
- 项目整体介绍(视频)
- 资源包使用说明(视频)【未登录】
- ETL过程实现(视频)【未登录】
- 数据预处理说明(视频)【未登录】
- 多维度指标分析(视频)【未登录】
- 将代码迁移到IntelliJ IDEA进行项目开发(视频)【未登录】