交通大数据分析项目(Hadoop + Hive数仓 + Spark SQL + Superset)
项目描述
综合运行大数据分析和可视化技术,对某城市地面交通刷卡数据(公交及地铁)进行OD分析,以找出客流潮汐特征,并结合经纬度图坐标在地图上展示OD线路。
项目架构
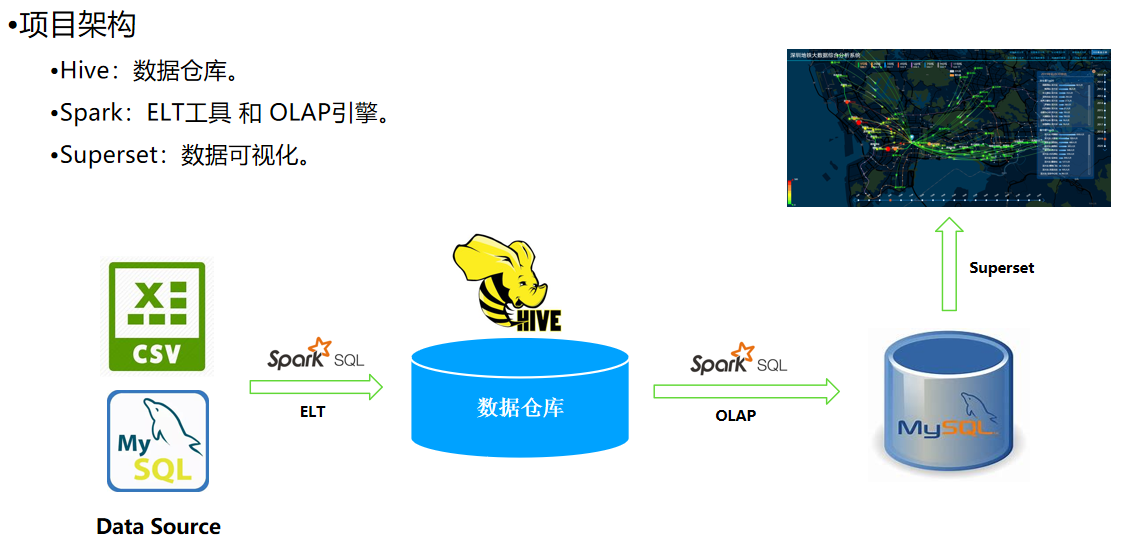
项目流程
项目流程说明如下:
- 1. 数据集:使用Spark ETL技术,将数据抽取到Hive数据仓库;
- 2. 大数据清洗:使用Spark SQL进行数据清洗和整理和数据整合;
- 3. 大数据分析:使用Spark SQL进行数据OD分析;
- 4. 大数据迁移:使用Spark ETL技术将OD结果抽取到MySQL数据库中;
- 5. 大数据可视化:使用Superset实现分析结果展示。
注:此项目可定制化改造,增加/修改如下功能
- 增加作业编排模块。
- 改用PySpark使用Python API进行数据清洗+分析,以及使用Python Flask + ECharts进行可视化展示;
- 改用Web程序对结果进行可视化展示,Spring MVC + ECharts等。
适用对象
本项目适合以下人员学习使用:
- 已有Spark基础,需要掌握大数据完整开发和分析流程、积累大数据项目经验;
- 大数据毕业设计项目。
项目实施过程
1. 数据采集本项目以文件形式和数据库形式,提供公交刷卡数据集、地铁刷卡数据集、公交站点数据、地铁站点数据。
2. 大数据清洗使用Spark对大数据进行清洗,包括去重、错误数据处理、空值处理、属性转换、属性提取、数据整合等数据预处理任务。
3. 大数据分析使用Spark SQL对用户出行OD进行分析。
4. 大数据ETL使用Spark ETL技术将分析结果导出到MySQL数据库中。
5. 大数据可视化使用Superset,展示分析结果。
项目源码下载
如果您是会员,并申请了终身会员权限,可下载本项目所有源码和测试数据。
您还未登录!(正式会员登录后可下载)
项目视频讲解
请点击下方链接,选择要播放的讲解视频。(注:正式用户登录方可观看全部项目视频)
- 数据ELT实现(视频)【未登录】
- 数据探索(视频)【未登录】
- 地铁刷卡数据集预处理(视频)【未登录】
- 公交刷卡数据集预处理(视频)【未登录】
- 数据整合(视频)【未登录】
- 用户出行OD识别(视频)【未登录】
- 用户出行OD分析(视频)【未登录】
- 将代码迁移到IDEA中进行工程化开发(视频)【未登录】
- 项目打包和部署(视频)【未登录】
- 定义Azkaban工作流(视频)【未登录】
- 执行Azkaban工作流(视频)【未登录】