Scala集合:Seq
Scala 有一个丰富的集合库,包含很多不同类型的集合。此外,所有的集合都暴露出相同的接口。因此,一旦熟悉了一个Scala 集合,就可以很容易地使用其它集合类型。
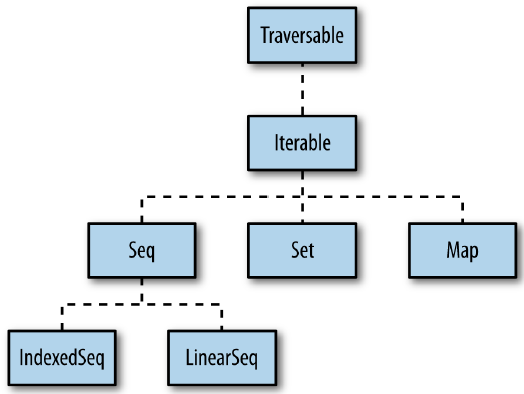
Scala中的集合体系主要包括:Iterable、Seq(IndexSeq)、Set(SortedSet)、Map(SortedMap)。其中Iterable是所有集合trait的根trait。实际上Seq、Set、和Map都是子trait。
- Seq:是一个有先后次序的值的序列,比如数组或列表。IndexSeq允许我们通过它们的下标快速的访问任意元素。举例来说,ArrayBuffer是带下标的,但是链表不是。
- Set:是一组没有先后次序的值。在SortedSet中,元素以某种排过序顺序被访问。
- Map:是一组(键、值)对。SortedMap按照键的排序访问其中的实体。
Scala中的集合是分成可变和不可变两类集合的。可变集合的内容或引用可以更改,不可变集合不能更改。这两种类型的集合分别对应Scala中的scala.collection.mutable和scala.collection.immutable两个包。
Scala明确区分了不可变和可变集合数据类型。不可变集合驻留在scala.collection.immutable包中,可变集合分别在scala.collection.mutable包中组织。毫无疑问,Scala支持不可变集合,并在不需要任何显式导入语句的情况下将它们添加到作用域中。
Scala编程语言提供了大量开箱即用的数据结构,可以将它们分组为Array、Map、List、Tree、Set和Queue。Scala中常用的集合如下表所示:
| 集合 | 描述 |
|---|---|
| List | 是一个相同类型元素的线性序列 |
| Set | 类型相同但没有重复的元素的集合 |
| Map | 键/值对的集合 |
| Tuple | 不同类型但大小固定的元素的集合 |
| Option | 包含0个或1个元素的容器 |
下面的代码简要描述了这几种集合形式:
val booksList = List("Spark","Scala","Python", "Spark")
val booksSet = Set("Spark","Scala","Python", "Spark")
val booksMap = Map(101 -> "Scala", 102 -> "Scala")
val booksTuple = new Tuple4(101,"Spark", "xinliwei","机械工业出版社",65.50)
Seq
序列表示一个以特定顺序排列的元素集合。因为该元素有个定义好的顺序,所以可以按照它们在集合中的位置进行访问。例如,可以请求序列中第n个元素。
Seq下包含了Range、ArrayBuffer、List等子trait。其中Range就代表了一个序列,通常可以使用“1 to10”这种语法来产生一个Range。 ArrayBuffer就类似于Java中的ArrayList。
序列有三个实现类,分别是Array、List和Vector。
1)Array(数组)
在Scala中,数组分为不可变数组和可变数组。不可变数组的实现类为Array,可变数组的实现类为ArrayBuffer。Array是一个索引的元素序列,有一个固定的长度。它是一个可变的数据结构;可以修改数组中的元素,不过,在一个Array被创建以后,不可以再向Array添加元素。Array中的元素有一个基于零的索引。要获得或更新一个元素,在括号内指定其索引。例如:
val arr = Array(10,20,30,40); arr(0) = 50; val first = arr(0);
在一个数组上的基本操作包含:
- 根据索引提取一个元素
- 使用索引更新一个元素
在下面的示例代码中,演示了数组的创建及操作:
// 1.Array 创建
var arr1 = new Array[Int](10)
var arr2 = Array(1, 5, 3, 7)
// 2.ArrayBuffer 创建
var arr3 = new ArrayBuffer[Int]()
var arr4 = ArrayBuffer(10, 50, 30, 70)
// 3.共同方法
println("---------Array 和 ArrayBuffer 共同方法----------");
println(arr2.sum) // 求和:16
println(arr2.max) // 求最大值:7
println(arr2.min) // 求最小值:1
println(arr2.mkString("|")) // 元素连接:结果是 1|5|3|7
println(arr2.sorted.toBuffer) // 1 3 5 7
println(arr2.reverse.toBuffer) // 7 3 5 1
println(arr4.toArray.getClass) // class [I
println(arr2.toBuffer.getClass) // class scala.collection.mutable.ArrayBuffer
println(Array(("cn", "china"), ("fr", "french")).toMap) // 将数组(元素是元组类型)转换为Map
// 4.ArrayBuffer 的独有方法
println("---------ArrayBuffer 独有方法----------");
arr4 += 20 // 增加一个元素
println(arr4) // 10 50 30 70 20
arr4 ++= Array(50, 60) // 增加一个数组集合
println(arr4) / /10 50 30 70 20 50 60
arr4.trimEnd(3) // 删除最后 3 个元素
println(arr4) // 10 50 30 70
arr4.insert(2, 28, 29) // 在索引2处插入两个元素
println(arr4) // 10 50 28 29 30 70
arr4.remove(2, 3) // 在索引2处删除三个元素
println(arr4) // 10 50 70
arr4.clear() // 清空数组
println(arr4)
// 5.遍历
println("-------5.遍历--------");
var arr5 = Array(1, 5, 3, 7)
// i) 直接取值
for (i <- arr5) {
println(i) // 1 5 3 7
}
// ii)通过下标
for (i <- 0 to arr5.length - 1) {
println(arr5(i)) // 1 5 3 7
}
// 多维数组
println("--------多维数组------")
var arr6 = Array(Array(1, 3, 5), Array(2, 4, 6))
for (i <- arr6) {
for(j <- i) {
print(j + " ")
}
print("\n")
}
下面的代码演示了在数组上的求和与排序:
// 1、求和与排序
println(Array(1,7,2,9).sum)
println("------------")
// 2、求最大值
println(ArrayBuffer("Mary","had","a","little","lamb").max)
println("------------")
// 3、排序
// 升序
val b = ArrayBuffer(1,7,2, 9)
val bSorted = b.sorted //1,2,7,9
b.sortWith(_<_).foreach(println)
println("------------")
// 降序
b.sortWith(_>_).foreach(println)
println("------------")
// 4、显示数组内容
println(b.mkString(" And ")) // 使用指定分隔符连接数组中的元素为字符串
println(b.mkString("<",",",">")) // <1,7,2,9>,指定前缀、分隔符、后缀
2)List(列表)
在Scala中,列表分为不可变的和可变的。不可变列表的实现类为List,可变数组的实现类为ListBuffer。List 是元素的一个线性序列。它是一个递归数据结构,不像数组,数组是一个扁平数据结构。另外,与数组不同,它是一个不可变的数据结构;List 被创建以后,不可以被修改,其大小以及元素不能被改变。List 是Scala 中最常用的数据结构之一。
Scala的List列表类似于数组,但是它们也有所不同:List列表是不可变的,值一旦被定义了就不能改变,其次列表具有递归的结构(也就是链接表结构)而数组不是。
虽然可以通过元素的索引来访问list 中的元素,但是通过索引访问元素不是一个高效的数据结构。访问时间与元素在list 中的位置成正比。
Scala的List是作为Linked List实现的,并提供有head、tail和isEmpty方法。因此,在List上的大多数操作涉及递归算法,将list拆分为head和tail部分。
创建List有两种方式:像Array一样,或者使用 :: 连接运算符。也可以将其他集合转换为List集合。下面的代码演示了创建一个列表的一些方式:
val xs = List(10,20,30,40);
val ys = (1 to 100).toList;
val zs = Array(1,2,3).toList;
// 创建一个空的List
val empty: List[Nothing] = List()
// 也可用Nil创建空的列表
val empty = Nil
// 创建图书列表
val books: List[String] = List("Scala从入门到精通", "Groovy从入门到精通", "Java从入门到精通")
// 使用tail Nil 和 :: 来创建图书列表
val books = "Scala从入门到精通" :: "Groovy从入门到精通" :: "Java从入门到精通" :: Nil
books.head // 第一个元素
books.tail // 除了第一个元素
【示例】不可变List列表的使用示例。
object ListDemo {
def main(args: Array[String]): Unit = {
println("1: 初始化一个不可变的List")
// val list1: List[String] = List("苹果","香蕉","葡萄干")
val list1 = List("苹果","香蕉","葡萄干") // 完全可以使用类型推断
println(s"list1中的元素有 = $list1")
println("\n2: 在特定的索引访问元素的不可变列表")
println(s"Element at index 0 = ${list1(0)}")
println(s"Element at index 1 = ${list1(1)}")
println(s"Element at index 2 = ${list1(2)}")
println("\n3: list是一个递归数据结构")
println(s"head of list is = ${list1.head}")
println(s"tail of list is = ${list1.tail}")
println("\n4: 使用 :+ 在不可变列表末尾添加元素")
// val list2: List[String] = list1 :+ "草莓"
val list2 = list1 :+ "草莓"
println(s"在末尾追加元素,使用 :+ = $list2")
println("\n5: 使用 +: 在不可变列表的前面添加元素")
// val list3: List[String] = "菠萝" +: list1
val list3 = "菠萝" +: list1
println(s"在不可变列表前端添加元素,使用 +: = $list3")
println("\n6: 使用 :: 将两个不可变列表添加在一起")
// val list4: List[Any] = list1 :: list2
val list4 = list1 :: list2
println(s"添加两个列表一起,使用 :: = $list4")
println("\n7: 使用 ::: 添加两个不可变列表在一起")
// val list5: List[String] = list1 ::: list2
val list5 = list1 ::: list2
println(s"添加两个列表一起,使用 ::: = $list5")
println("\n8: 初始化一个空的不可变列表")
// val emptyList: List[String] = List.empty[String]
val emptyList = List.empty[String]
// val emptyList = List()
// val emptyList = Nil
println(s"Empty list = $emptyList")
}
}
可以使用iterator方法对集合进行迭代。iterator.hasNext方法用于查找集合是否具有进一步的元素,而iterator.next方法用于访问集合中的元素。下面的代码描述了iterator方法:
val booksList = List("Spark","Scala","Python","Spark")
// val booksList = Array("Spark","Scala","Python","Spark")
def iteratingList(booksList:List[String]){
val iterator = booksList.iterator
while(iterator.hasNext){
println(iterator.next)
}
}
iteratingList(booksList)
执行以上代码,输出结果如下所示:
Spark Scala Python Spark
在一个list 上的基本操作包括:
- head方法:提取第一个元素;
- tail方法:提取除第一个元素之外的所有元素;
- isEmpty方法:判断一个list 是否为空。如果一个list 是空的,该方法返回true。
下面的代码演示了List上的常用操作:
// 1、在Scala中,列表要么是Nil(及空表),要么是一个head元素加上一个tail,而tail又是一个列表
val list = List(1, 2, 3, 4, 5)
list.head
list.tail
list.isEmpty
list == Nil
// 下面是一个使用递归求list集合中和的例子:
def recursion(list:List[Int]):Int = {
if(list.isEmpty) {
return 0
}
list.head + recursion(list.tail)
}
// 增
/* A.++(B) --> 在列表A的尾部添加另外一个列表B,组成一个新的列表
* A.++:(B) --> 在列表A的首部添加另外一个列表B,组成一个新的列表
* A.:::(B) --> 在列表A的首部添加另外一个列表B,组成一个新的列表
* ------
* A.:+ (element) -->在列表A的尾部添加一个element,组成一个新的集合
* A.+: (element) -->在列表A的首部添加一个element,组成一个新的集合
* A.:: (element) -->在列表A的首部添加一个element,组成一个新的集合
*/
val left = List(1, 2, 3, 4)
val right = List(5, 6, 7)
left.++(right)
left.++:(right)
left.:::(right)
left.:+(10)
left.+:(10)
left.::(10)
// 删除
// drop(n) --->删除list的前n个元素(首部开始删除)
// dropRight(n) --->删除list的后n个元素(尾部开始删除)
// dropWhile(p: A => Boolean) --->逐个匹配去除符合条件的元素,直到不符合条件,之后的元素不再判断
val list = List(1, 2, 3, 4, 5, 6, 7)
list.drop(2)
list.dropRight(3)
list.dropWhile(_ <= 3)
list.dropWhile(_ > 3) // 第一个元素就不符合条件,后面的不再判断,所以一个也没有删除
val list = List(1, 2, 13, 14, 15, 6, 7)
list.take(5)
list.takeWhile(_ <= 3)
list.takeWhile(_ > 3) // 获取的是最满足条件的最长前缀
list.mkString
list.mkString(";")
list.count(_ % 2 == 0)
val fruit = "apples" :: ("oranges" :: ("pears" :: Nil)) // ::操作符从给定的头和尾部创建一个新的列表
val list1 = List(1, 2, 3)
val list2 = List(4, 5, 6)
list1 ++ list2 // ++两个集合之间的操作
list1.sum
下面的代码示例中,演示了列表的创建及操作:
//1. List 创建
// 方式一:
var list1 = List("aa", "bb", "ccc")
list1(0)
list1(1)
list1(2)
// list1(0) = "aaaaa" // 不可以,因为List不可以改变
//方式二:右操作符:当方法名以:结尾时,为右操作符,先做右边
// :: 右操作符,拼接元素
var list3 = "aa" :: "bb" :: "cc" :: Nil // Nil 是空集合,先做"cc"::Nil,其中::是 Nil 的方法
var list4 = list1 ::: "dd" :: Nil // :::拼接集合
// 还可以
val x = List.tabulate(5)(n => n * n)
x.foreach(println)
val y = List.range(1, 10) // 1 - 9
y.foreach(println)
// 2.方法
// 检索数据
// head() 第一个元素
list1.head
// tail() 除了第 1 个元素外的全部元素
list1.tail
list1.tail.head
list1.tail.tail
// take(n) 取前 n 个元素 - 子集
list1.take(2)
// init() 除了最后一个的全部元素
list1.init
// 3.ListBuffer 创建
import scala.collection.mutable.ListBuffer
var list5 = ListBuffer("111", "222", "333")
// 增
// +=或 append 追加元素
list5.append("444")
list5 += "555"
// list5 += ("666","777")
list5 :+ "000"
"000" +: list5
// ++= 追加数组/列表
list5 ++= List("666", "777")
// 丢弃前 3 个元素
list5.drop(3)
// 判断是否为空
list5.isEmpty
// 翻转
list5.reverse
// splitAt(m): 把列表前m个做成一组,后面做为另一组。返回的是一个Tuple2(ListBuffer, ListBuffer)
list5.splitAt(3)
// flatten: 扁平化
var list6 = List(List('a', 'b'), List('c'), List('d'))
list6.flatten
// 转换成数组
list5.toArray
// zip:两个 List 内部的元素合并 - 拉链方法
var list7 = List(1, 2, 3).zip(List(4, 5, 6))
// grouped(n):每 n 个元素分成 1 组,返回是迭代器 Iterator,可以再用 toList 转成 list 类型
List(1, 3, 5, 7, 9).grouped(2).foreach(println)
List(1, 3, 5, 7, 9).grouped(2).toList
println("---------------")
// 遍历方式一:不推荐
for (e <- List("88", "99")) {
println(e)
}
println("---------------")
// 遍历方式二:使用foreach,推荐,这才是采用函数式编程
List("88", "99").foreach(e => println(e)) // foreach是高阶函数
println("---------------")
List("88", "99").foreach(println(_)) // 简化写法 _占位符
println("---------------")
List("88", "99").foreach(println) // 最简方法
