使用PyCharm开发PySpark应用程序
本章主要内容:
要开发PySpark应用程序,通常可以采用以下几种开发方式和开发环境:
- 使用pyspark shell,交互式执行;
- 使用PyCharm IDE集成开发环境,先开发测试,然后部署执行;
- 使用Jupyter Notebook,交互式开发;
- 使用Zeppelin Notebook,交互式开发。
在上一章,我们已经了解了如何使用pyspark shell以交互式方式执行PySpark代码。但是pyspark shell并不适合在生产(工作)环境下使用。在生产(工作)环境中,我们可以根据自己的需求选择后面三种开发和执行方式。
推荐:为避免繁琐易错的配置,推荐直接下载使用小白学苑提供的PBLP个人大数据学习平台。该平台已经配置好了Hadoop + PySpark + Zeppelin + Jupyter的大数据学习和开发环境。
在这一节,向大家介绍如何使用PyCharm这个IDE来开发PySpark应用程序。 我们将使用PyCharm Community Edition作为IDE。在本教程的最后,将了解如何使用PyCharm设置PySpark,以及如何将代码部署到集群中。
准备数据文件
接下来,我们将构建一个简单的PySpark应用程序,用来对莎士比亚文集(shakespeare.txt)执行单词计数任务。莎士比亚文集(shakespeare.txt)位于PBLP平台的/home/hduser/data/spark/目录下。
我们需要在两个地方使用这个shakespeare.txt数据集。一个在项目开发中用于本地程序测试,另一个在HDFS (Hadoop分布式文件系统)中用于集群测试。
先将PBDP大数据平台中的/home/hduser/data/spark/shakespeare.txt文件上传到HDFS:
- 1)确保已经启动了HDFS集群;
- 2)在终端窗口中,执行以下命令,上传文件到HDFS上:
$ cd /home/hduser/data/spark $ hdfs dfs -put shakespeare.txt /data/spark/
安装PyCharm
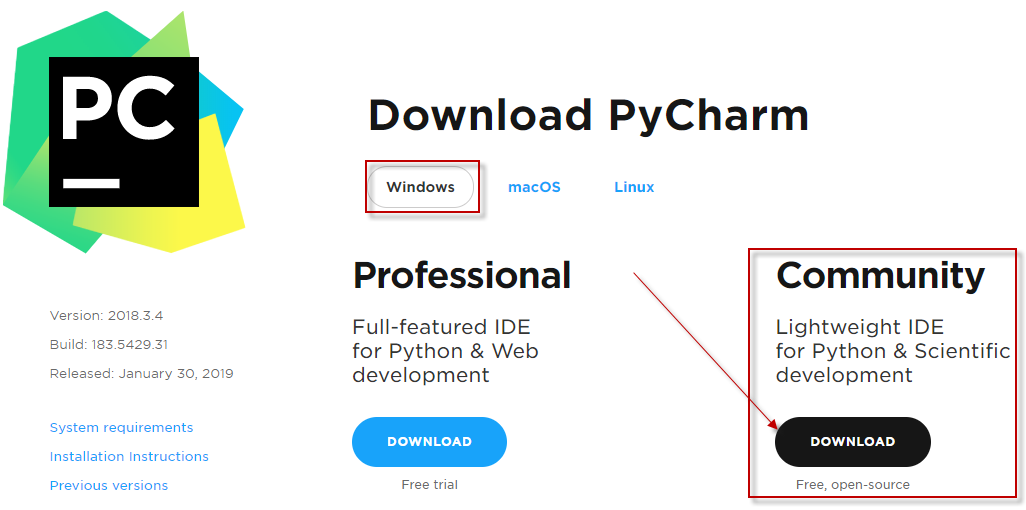
1、首先去Pycharm官网,下载PyCharm安装包(去官网下载),根据自己电脑的操作系统进行选择。PyCharm分为收费的企业版和免费的社区版。开发PySpark应用程序,使用社区版即可。对于windows系统选择下图的框选的安装包。
2、双击下载的安装包,进行安装。一路Next即可。安装完成,会在电脑桌面生成如下的启动图标,双击它可以启动PyCharm:

3、下面是PyCharm中常用的一些快捷键:
- Ctrl + Enter:在下方新建行但不移动光标;
- Shift + Enter:在下方新建行并移到新行行首;
- Ctrl + /:注释(取消注释)选择的行;
- Ctrl+d:对光标所在行的代码进行复制。
创建一个新的PyCharm项目
要创建一个新的项目,首先启动PyCharm,选择File > New Project,选择Pure Python,并在右侧指定项目代码所在的位置,将项目命名为HelloSpark。单击Create按钮创建此项目。
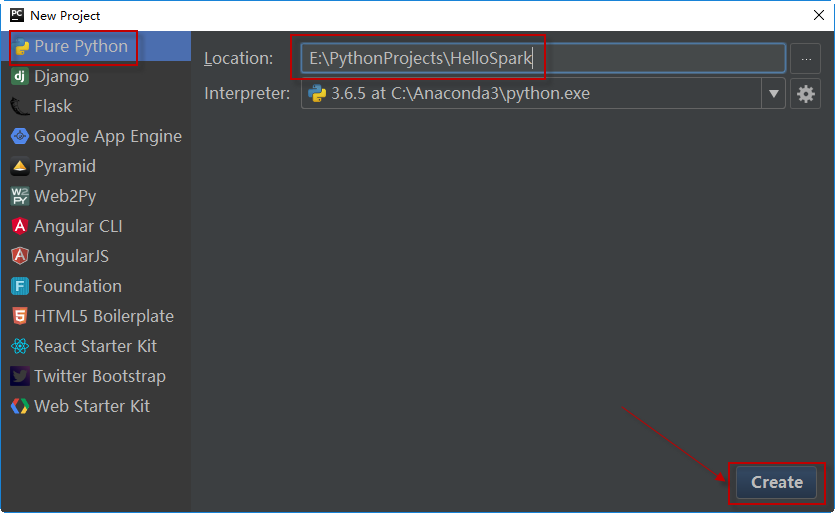
这样就创建了一个空的项目HelloSpark。
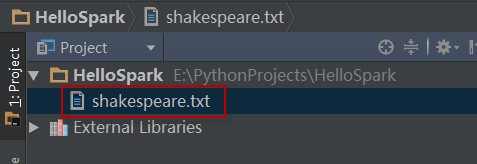
在本地文件系统,将shakespeare.txt拷贝到项目的根目录下,比如~/PythonProjects/HelloSpark。如下图所示:
安装pyspark包
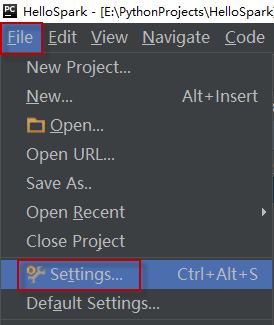
要安装pyspark包,请在PyCharm中导航到File > Settings ...,打开项目设置面板,如下图所示:
在项目设置面板中,选择左侧的Project:HelloSpark > Project Interpreter,然后在右侧单击右边栏的绿色+按钮:
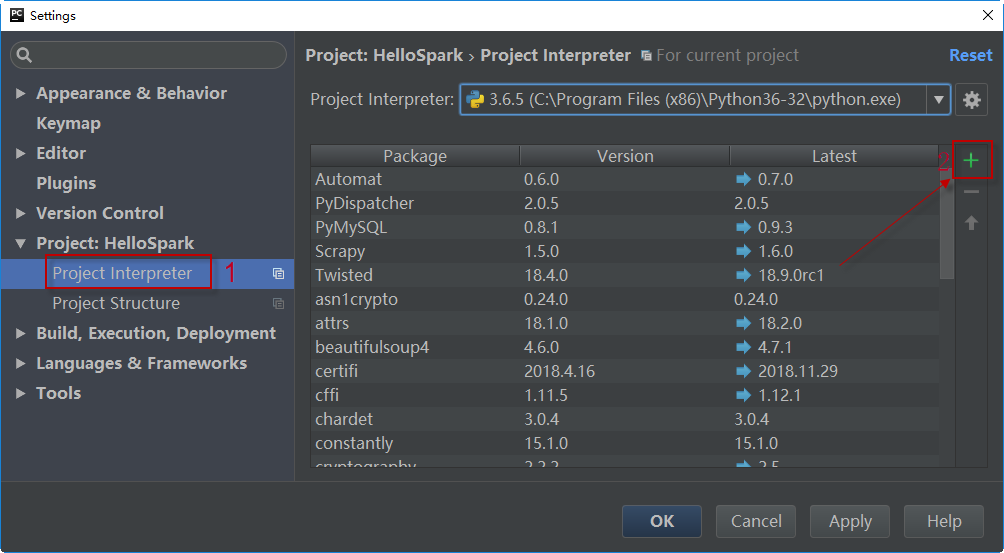
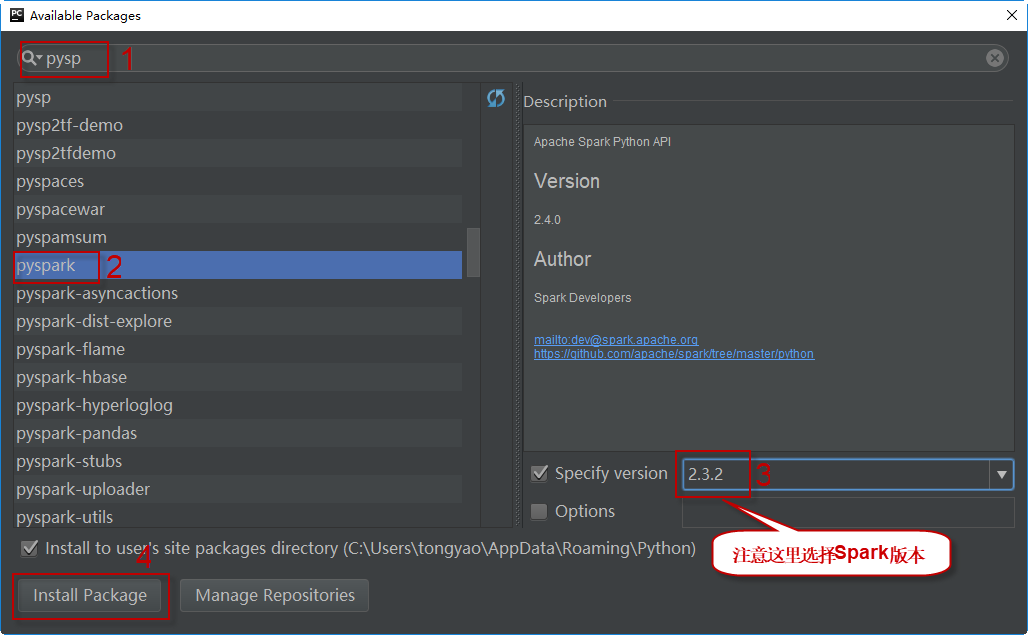
在上方的搜索框内输入pyspark,搜索并选择pyspark,然后的面板右侧选择指定的版本(说明:虽然截图中显示版本是2.3.2,实际上本书所有示例使用的Spark版本均是基于3.1.2),最后单击单击Install Package按钮安装。如下图所示:
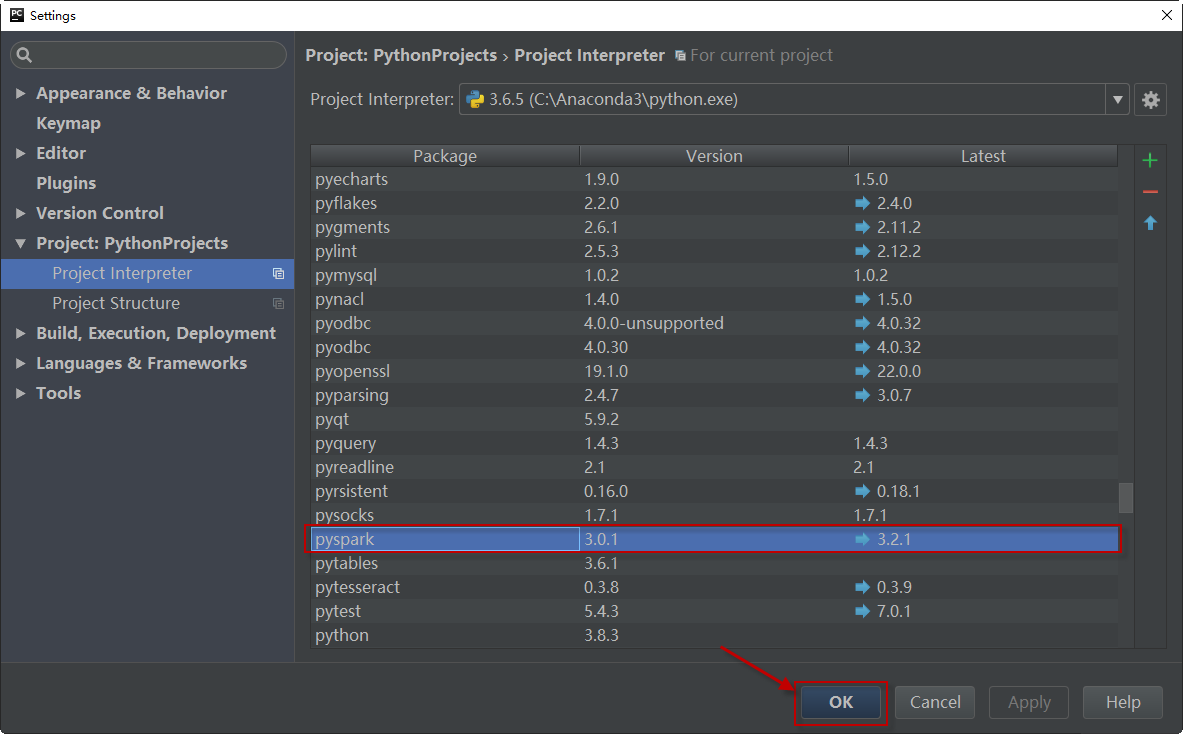
安装完毕,关闭此面板,回到settings界面,可以看到pyspark已经安装成功。单击OK按钮即可。
创建PySpark应用程序
在刚创建的HelloSpark项目目录上,单击右键,选择New > File,创建一个新的Python源文件,并命名为Main.py。

编辑Main.py文件内容如下:
from pyspark.sql import SparkSession
# 构建SparkSession和SparkContext实例
spark = SparkSession.builder \
.master("local[2]") \
.appName("MyFirstStandaloneApp") \
.getOrCreate()
# 加载数据文件
text_file = spark.sparkContext.textFile("./shakespeare.txt")
# 进行单词计数
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
print ("元素数量: " + str(counts.count()))
# 将统计结果保存到指定文化中
counts.saveAsTextFile("./shakespeareWordCount")
要运行程序,请从IDE菜单中单击Run > Run…并选择Main。如下图所示:

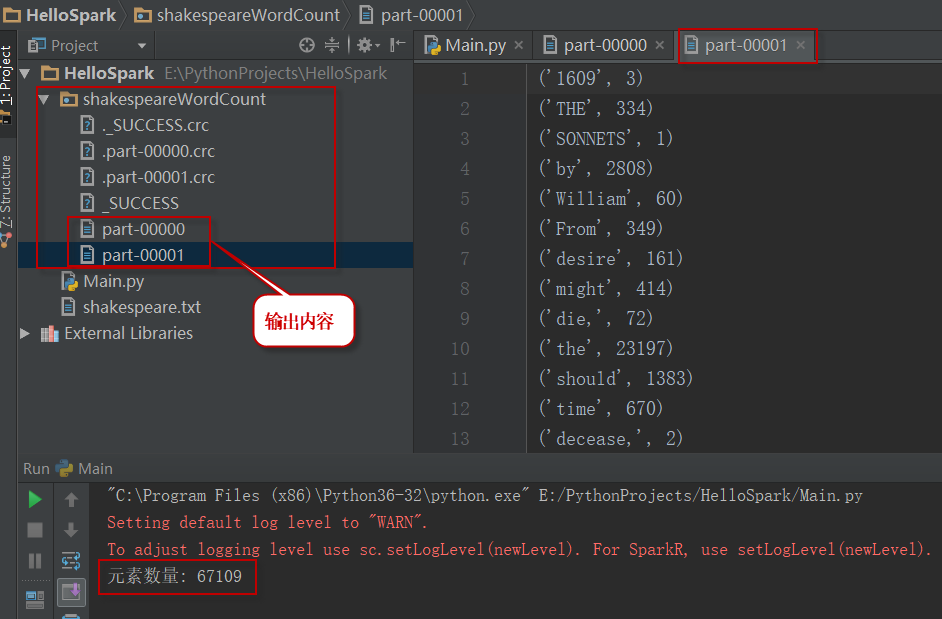
程序计算结果保存在shakespeareWordCount文件夹中,该文件夹与源代码的文件夹位于相同的目录下。如下图所示:
部署到集群中运行
接下来我们将PySpark作业部署到集群上运行。
1)首先,需要修改源代码,从HDFS中读取数据集而不是从本地 PyCharm项目读取。如下面的代码所示:
from pyspark.sql import SparkSession
# 构建SparkSession和SparkContext实例
spark = SparkSession.builder \
.master("local[2]") \
.appName("MyFirstStandaloneApp") \
.getOrCreate()
# 加载HDFS上的数据文件
text_file = sc.textFile("hdfs://xueai8:8020/data/spark/shakespeare.txt")
# 进行单词计数
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
print ("元素数量: " + str(counts.count()))
# 将统计结果保存到指定文化中
counts.saveAsTextFile("hdfs://xueai8:8020/data/spark/shakespeareWordCount")
2)接下来,将Main.py拷贝到虚拟机上。
3)最后,使用spark-submit提交Main.py到Spark集群上运行:
$ spark-submit ./Main.py
4)输出结果被保存到HDFS上:/data/spark/shakespeareWordCount。其内容如下:
(u'fawn', 11) (u'Fame,', 3) (u'mustachio', 1) (u'protested,', 1) (u'sending.', 3) (u'offendeth', 1) (u'instant;', 1) (u'scold', 4) (u'Sergeant.', 1) (u'nunnery', 1) (u'Sergeant,', 2) ...