项目:农业大数据项目-基于hadoop的水果产量数据分析与可视化系统
项目简介
基于hadoop进行了农业大数据系统平台的设计。首先python爬虫对数据进行抓取,后存储到hadoop/hdfs分布式文件系统然后通过ELT的方式将数据抽取到Hive数仓,使用Spark SQL + Hive数仓实现数据清洗、整理与分析,最后使用Spark SQL将分析结果导出到MySQL数据库,最后使用智慧大屏多维度呈现农业大数据相关分析结果。
使用的技术栈:Python爬虫 + Hadoop + Spark + Hive + DataGear
项目详情
项目描述
本项目的研究主题是基于hadoop的水果产量数据分析与可视化系统的设计与实现,研究范围是以我国农业的水果产业为例,通过对水果产量和诸多关联指标数据进行聚合和数据可视化实现对水果类的分析。例如通过果园的种植面积与水果产量、灾害面积与水果产量、进口与出口数量等关系图表,从而得到一些指导农业生产的依据以实现农业的增产增收。
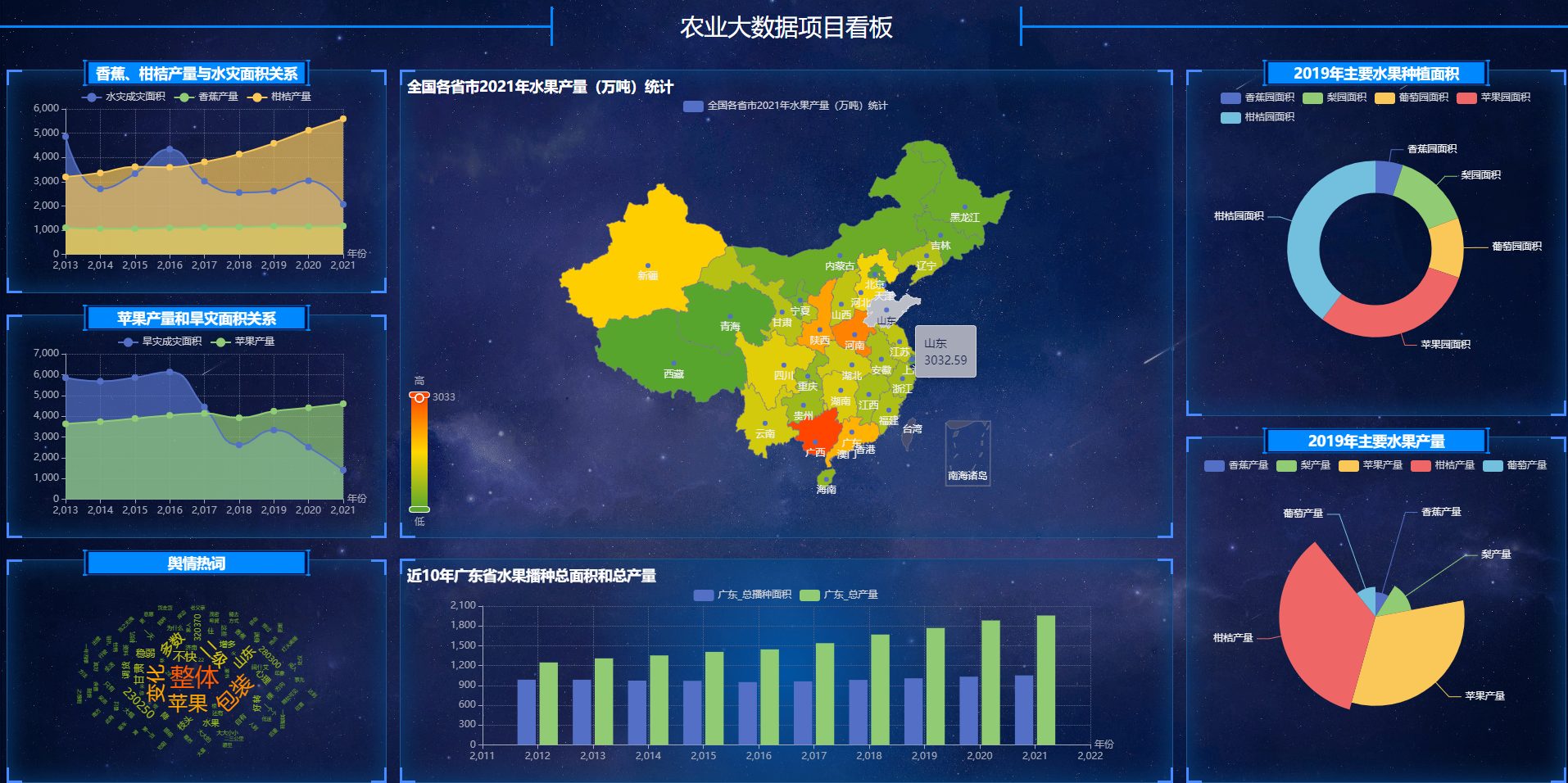
项目最终可视化展示结果如下图所示:
项目架构
- 1.数据采集:Python爬虫程序。
- 2.数据存储:Hadoop/HDFS分布式文件系统。
- 3.数据ELT:使用Spark实现数据ELT到Hive数据仓库。
- 4.数据清洗、整理与分析:使用Spark SQL + Hive数仓实现。
- 5.数据导出:使用Spark SQL将分析结果导出到MySQL数据库。
- 6.数据可视化:通过DataGear智慧大屏多维度呈现农业大数据相关分析结果。
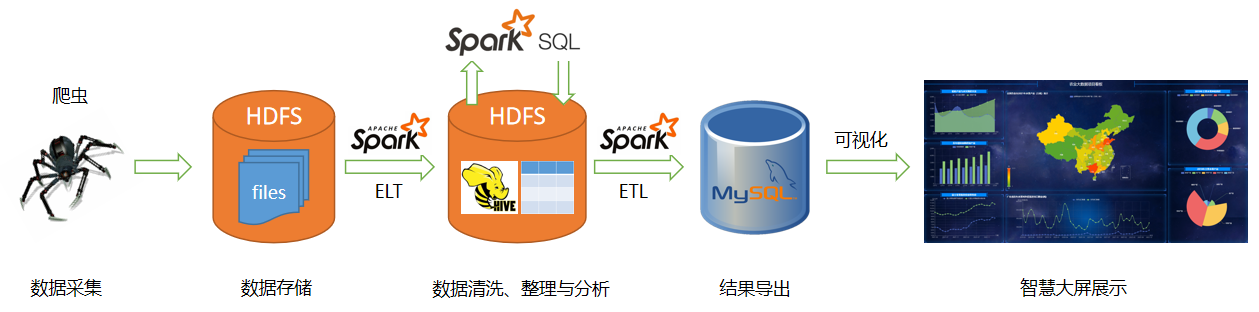
项目流程
项目流程说明如下:
- 1. 数据采集:使用Python爬虫程序采集互联网公开的信息数据。本系统的数据来源于国家统计局、中国农业部、全国重点农产品市场信息等平台。分为两个模块概述:一是年度瓜果类统计指标数据,数据类型是年度农业相关统计指标,包括最近10年的果园面积、瓜果类面积、茶园面积、茶叶、各省份的水果产量、瓜果类单位面积产量、受灾和成灾面积、有效灌溉面积、农用化肥施用量、播种面积等。二是月度进出口贸易数据与水果价格,数据类型包括各地区的进口量,进口金额,出口量,出口金额,水果的集贸市场价格,批发价格。
- 2. 数据存储:采用Hadoop/HDFS分布式文件系统 + Hive数据仓库。
- 3. 数据ELT:使用Spark实现数据的ELT过程,使用Hive数仓存储中间数据;
- 4. 数据预处理:使用Spark SQL + UDF进行数据清洗和整理。首先从Hive ODS层加载数据,对数据(编码指标、水果商品历年播种面积和产量数、富士苹果批发价格月度数据和集贸市场价格月度数、全国各省份直辖市月度水果进出口贸易)进行探索,然后基于探索情况进行清洗和整理,最后将整理后的省份编码数据写入到DWD的维表中。
- 5. 数据分析:使用Spark SQL进行数据多维度分析。数据分析的目的是寻找出与产值等最可能具有直接相关的因素,从而得到一些指导农业生产的依据以实现农业的增产增收。
- 6. 结果导出:使用Spark实现数据从HDFS导出到MySQL数据库的ETL过程;
- 7. 数据可视化:使用开源可视化框架将分析结果展示在Web大屏上。
适用对象
本项目适合以下人员学习使用:
- 已有Spark基础,需要掌握大数据完整开发和分析流程、积累大数据项目经验;
- 大数据毕业设计项目。
项目视频
本项目暂无视频。请根据代码和文档学习。
本项目本站提供开发和部署在线指导。下载此项目的会员,在开发、部署过程中遇到问题,可联系本站技术辅导咨询。
热门项目
- 某招聘网站招聘大数据分析案例(Spark实现) (61次下载)
- 某招聘网站招聘大数据分析案例(Hive实现) (58次下载)
- 电商大数据-淘宝双十一美妆销售分析项目 (47次下载)
- 某招聘网站招聘大数据分析案例(PySpark实现) (37次下载)
- 某物流公司运输车辆超速实时检测案例 (27次下载)
挣积分
用户可以上传项目资源到本站,我们会根据资源的质量和价值计算积分给用户。
用户可以使用自己账号下的积分换取本站VIP资源(教程、项目、图书等)。
请联系我们
- Email:zz_kapper@163.com
- QQ:185314368(张老师)