2023年国赛_赛项规程样题解析-数据采集与实时计算_子任务一:实时数据采集
该子任务的实现没有什么变化,放在这里是为了整个系列的完整性。
环境说明
服务端登录地址详见各模块服务端说明。
补充说明:各主机可通过Asbru工具或SSH客户端进行SSH访问;Flink任务在Yarn上用per job模式(即Job分离模式,不采用Session模式),方便Yarn回收资源。
子任务
子任务说明
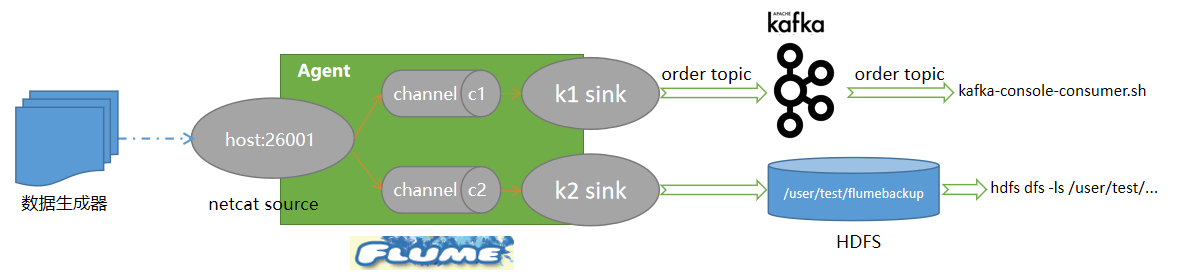
1. 在主节点使用Flume采集实时数据生成器10050端口的socket数据,将数据存入到Kafka的Topic中(Topic名称为order,分区数为4),使用Kafka自带的消费者消费order(Topic)中的数据,将前2条数据的结果截图粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下;
2. 采用多路复用模式,Flume接收数据注入kafka 的同时,将数据备份到HDFS目录/user/test/flumebackup下,将查看备份目录下的第一个文件的前2条数据的命令与结果截图粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下。
实现原理
技术参考1:......
抱歉,只有登录会员才可浏览!会员登录